Overview
Description
DRP-AI for RZ/V2H and RZ/V2N supports a feature for efficiently calculating the pruned AI model. The DRP-AI Extension Pack provides a pruning function optimized for RZ/V2H and RZ/V2N. The DRP-AI optimized pruning function can be used in combination with this tool and PyTorch or TensorFlow training code.
What is pruning?
Nodes in a neural network are interconnected as shown in the figure. Methods of reducing the number of parameters by removing weights between nodes or removing nodes are referred to as “pruning”. A neural network to which pruning has not been applied is generally referred to as a dense neural network. And a neural network to which pruning has been applied is generally referred to as a sparse neural network. Applying pruning leads to a slight deterioration in the accuracy of the model but can reduce the power required by hardware and accelerate the inference process.
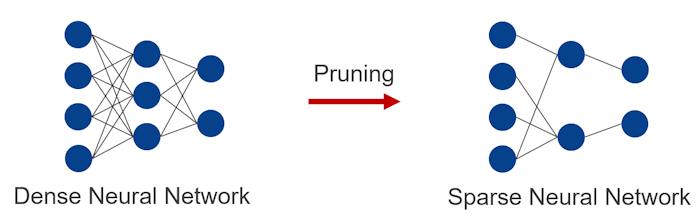
How to embed the pruned model
The pruned model can be embedded using DRP-AI TVM. Refer to the DRP-AI TVM page on GitHub for details on TVM.
https://github.com/renesas-rz/rzv_drp-ai_tvm
Note: As shown in the figure, pruning is an optional function. (Dense model also can be embedded.)

Features
- Pruning functions optimized for RZ/V2H and RZ/V2N
- Pruning ratio can be specified for balance between accuracy and power efficiency
- Supports 2 pruning modes for improving accuracy (One Shot/Gradual)
Release Information
DRP-AI Extension Pack Version 1.3.0 is available (Jan 2026)
- The packaging format has been updated to a wheel, eliminating the need for manual configuration of environment variables.
- The TensorFlow and PyTorch versions can now be installed separately.
Target Devices
Downloads
|
|
|
|
|---|---|---|
| Type | Title | Date |
| Software & Tools - Software | DRP-AI Extension Pack (Pruning Tool) Version 1.3.0
|
|
1 item
|
||
Documentation
|
|
|
|
|---|---|---|
| Type | Title | Date |
| Manual - Software | PDF 1.78 MB | |
| Application Note |
PDF
440 KB
AI-generated Summary:
The guide explains how to measure the processing speed improvements of sparse AI models created by pruning dense models without retraining. It outlines a three-step process: preparing dense and sparse models using PyTorch or TensorFlow, converting them with DRP-AI TVM, and running performance tests on hardware. The document includes example code for pruning with PyTorch and details the operating environment and related resources. It focuses on quickly confirming speed gains from pruning rather than accuracy evaluation.
|
|
2 items
|
||
Design & Development
Related Boards & Kits

RZ/V2H Quad-core Vision AI MPU Evaluation Kit
The RZ/V2H AI MPU evaluation kit (RTK0EF0168C04000BJ) is used to evaluate Renesas' RZ/V2H quad-core vision AI MPU. The kit includes a CPU board and an expansion (EXP) board. It supports RZ/V2H standard software packages and enables easy implementation of software development tasks such as low... Read More
Test This Board Remotely

RZ/V2N Quad-core Vision AI MPU Evaluation Kit
The RZ/V2N AI MPU Evaluation Kit V2.0 (RTK0EF0186C03001BJ) is used to evaluate our RZ/V2N quad-core vision AI MPU. The kit includes a CPU board and an expansion board (EXP board). V2.0 adds support for the DDR Suspend to RAM function, and the power supply circuit configuration has been changed... Read More
Videos & Training
This video provides an overview of DRP-AI TVM, focusing on the integration of AI into "Endpoint" devices for efficient real-time processing. Renesas' DRP-AI acts as a powerful accelerator, offering key features that enhance the performance and capabilities of endpoint AI applications.
Support

Support Communities


