
If you have ever attempted or completed a machine learning project using sensor data, you probably know already that data collection and preparation is both the most costly part of the project and also the place where you are most likely to go off track. Problems with data consistency and quality, holes in coverage, undetected issues with instrumentation, faulty pre-processing — all of these are common pitfalls that can render an entire data set completely useless, and often go undiscovered until collection is wrapped and the analysis phase has begun. Or, rather, tried to begin.
Since these pitfalls are so common, our Reality AI machine learning software contains functionality to keep data collection on track, in terms of both scope and budget, and to help avoid these common pitfalls. Because the best way to manage the cost of your data collection is to make sure you only need to do it once.
Data Collection Monitoring
A very common issue we see in data collection efforts is the failure to monitor data collection and spot problems early. Issues with instrumentation, file capture, and other technical snags happen often. If left undetected until the data analysis step, after the collection is complete, you risk needing to discard entire data sets. More than once, we have seen projects need to start over from scratch due to minor instrumentation or processing issues that, though easily correctable, rendered all of the data unusable.
That is why Reality AI Tools® includes functionality to monitor the status of data collection automatically, tracking consistency, quality, and coverage.
Reality AI Tools: Automated Data Readiness Assessment
Every time a new source data file is added to a project in Reality AI Tools, the system reads the file, parses it, and looks for issues. If any are found, they generate immediate user alerts. The system also generates statistics that can be used to identify trends and report on progress.
Reality AI Tools Data Readiness reports on:
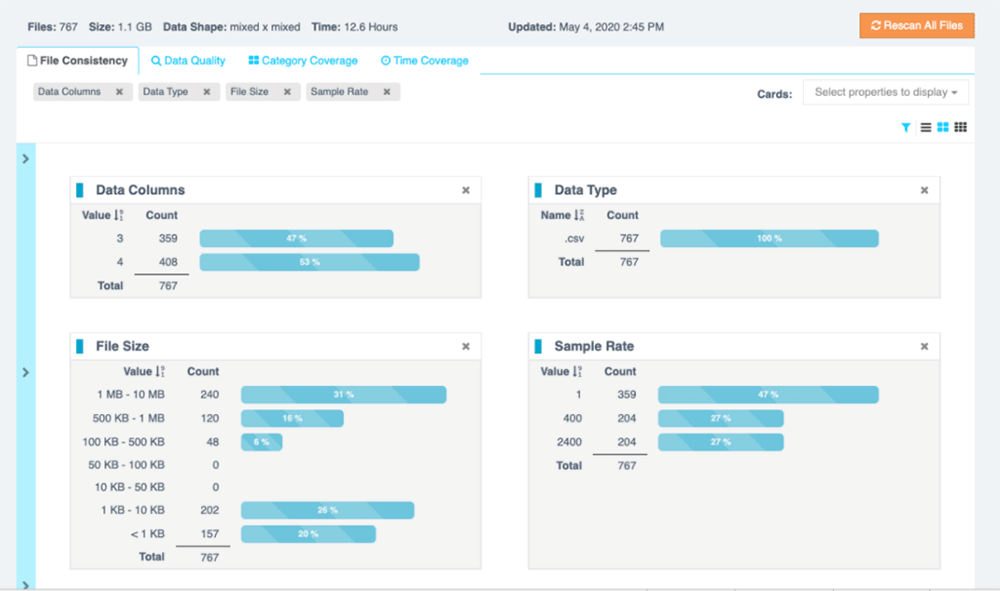
File Consistency
File size, file type, number of data columns, sample rate, and other file-level demographics. Inconsistencies in these categories can indicate systemic problems in data collection or in post-collection processing.
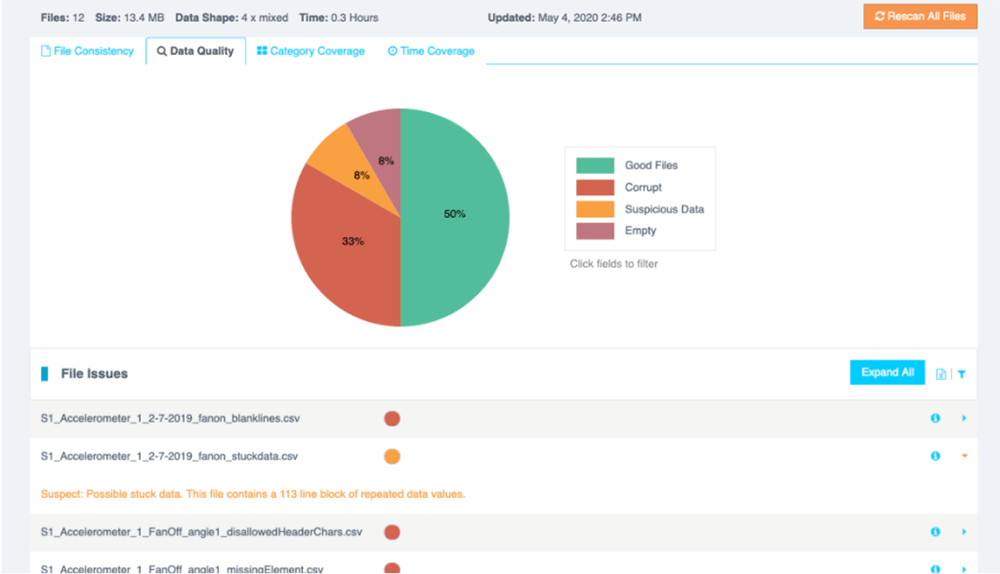
Data Quality
Issues that prevent a file from being read, such as corrupted files, invalid characters, blank rows, and missing data elements. It also looks for suspicious data, such as blocks of data with repeating patterns or zeros.
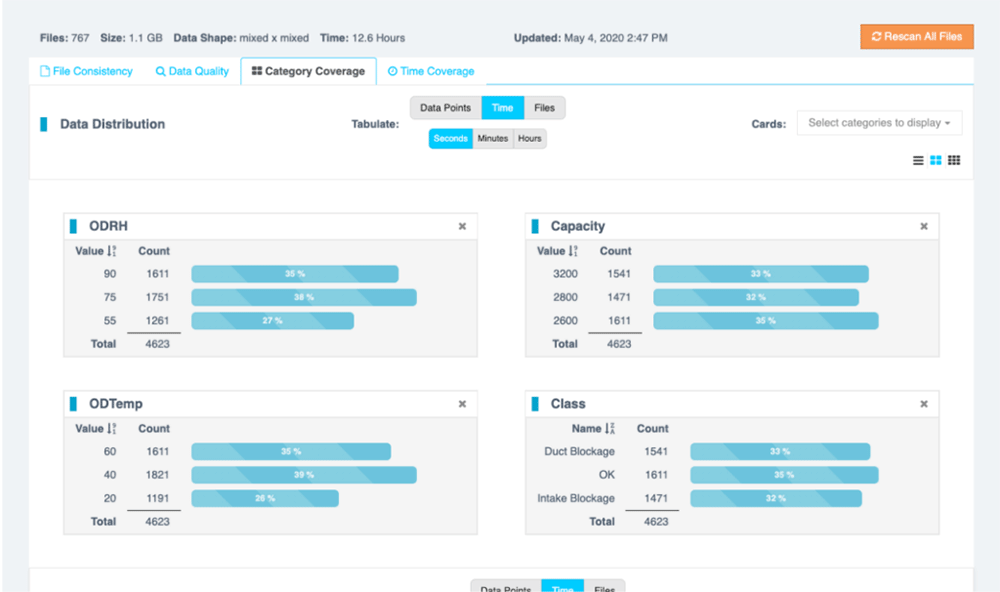
Data Coverage
Cumulative statistics showing how much data has been collected for key target and metadata categories – can be used to track progress vs the Data Coverage Matrix in a Data Collection Plan.
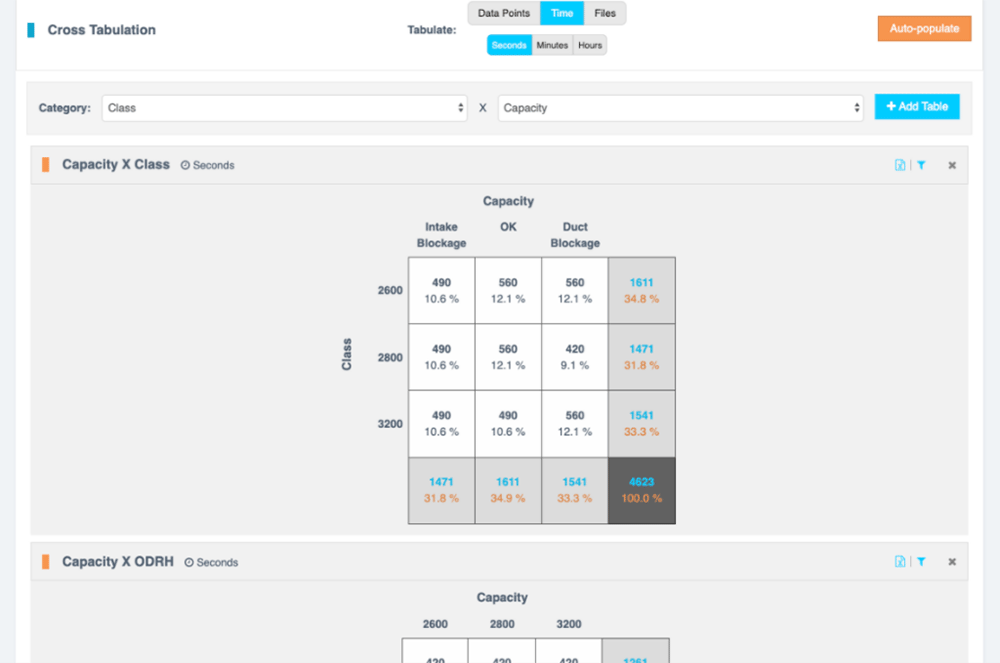
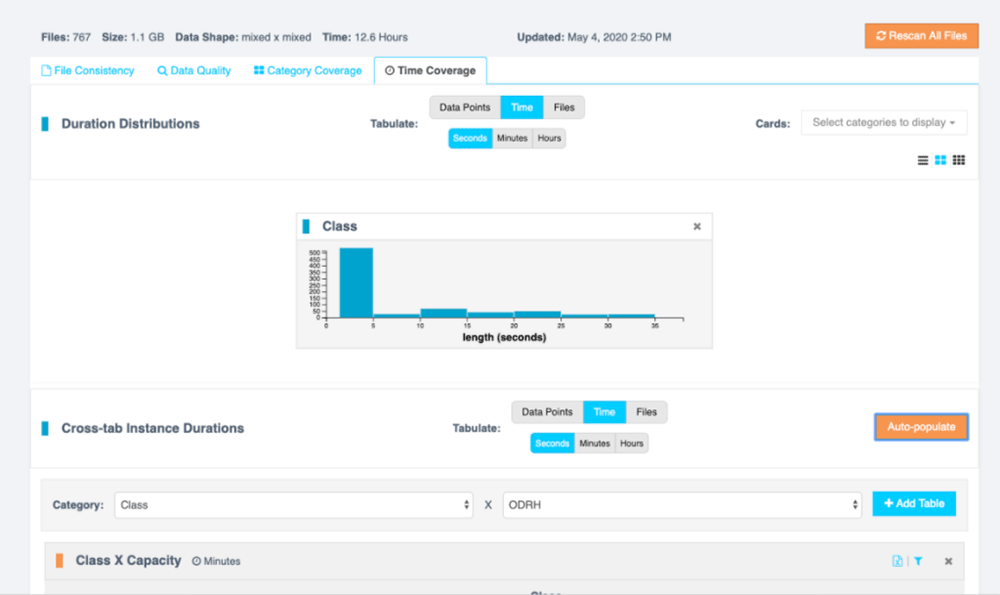
Time Coverage
Cumulative statistics describing data in terms of time-in-class for key target and metadata categories. This is particularly useful for looking at data coverage for real-time streaming applications when the length of the decision window or smoothing methods are under evaluation.
Data Collection Process
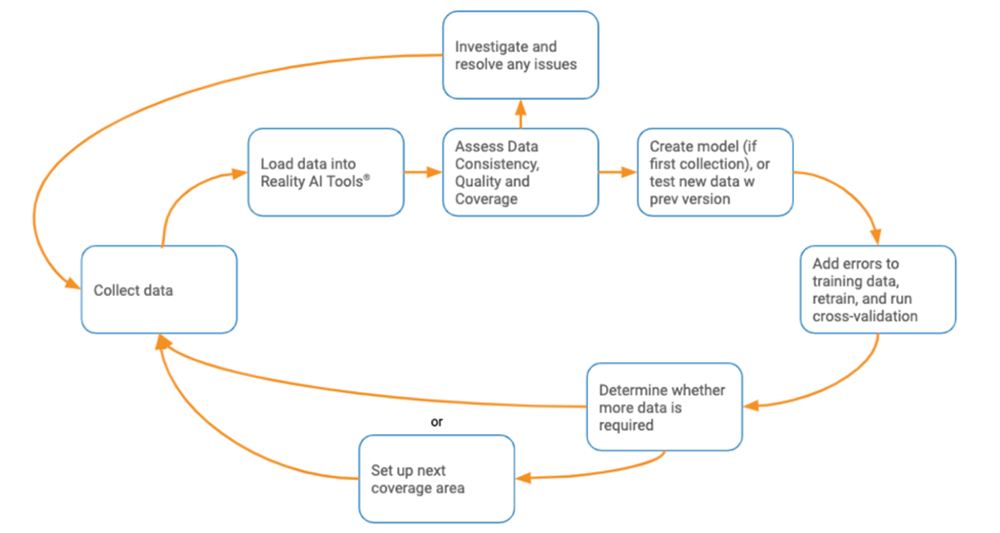
Using Reality AI Tools for automated data readiness assessment and generation of machine learning models, it is easy to implement an Iterative Data Coverage process to guide your data collection.
With Iterative Data Coverage, you begin by collecting data for a specific scope of coverage (keep an eye out for our upcoming whitepaper on Data Collection for more on defining data coverage), test the most recent version of the model to evaluate how well it works on this new area, add any mistakes to the training set, and move on to the next area, pausing when testing indicates that more data is needed for adequate performance and generalization.
Iterative Data Coverage with Reality AI Tools
This kind of process is easy to implement using Reality AI Tools. For each coverage area, you initiate data collection and regularly run Data Readiness Assessment in Reality AI Tools. Any issues uncovered can be resolved quickly, and good data can be tested on the most recent version of the ML model. If accuracy is good, you can conclude that the model is generalizing well to the current coverage area. If not, additional data from this coverage area may be required. In any event, errors made by the model should be added to the training set and the model retrained.
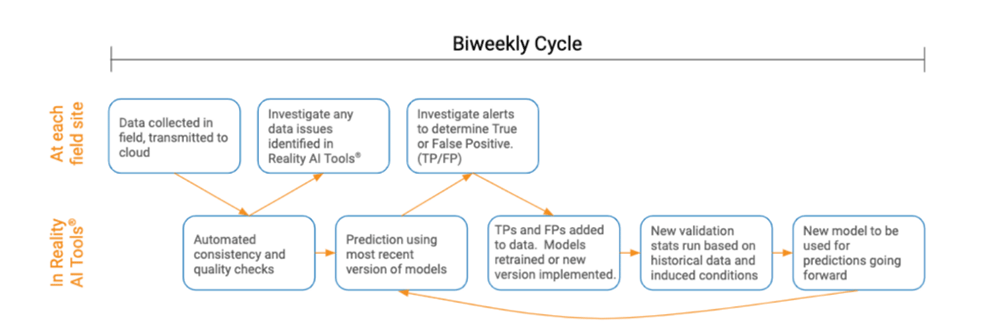
When doing extended field testing, you may want to run a similar process. Here the objective is also to ensure that collected data is high quality and that ML models can be continuously improved. When error rates are within acceptable limits for the use case, testing is complete.
Knowing Where You're Going So You Don't Wind Up Somewhere Else
Any proper collection starts with a data collection plan, as we covered in a previous blog post and in our Data Collection whitepaper. But once you start in the lab or the field, make sure everything throughout the process checks out and there are no red flags as the data comes in. Make sure you catch problems early, so you can correct them with minimal impact to the budget or the plan.
Keep things on track, and then use a process like Iterative Data Collection to further optimize data coverage and the cost of collection by spending your time and effort where it does the most good — in coverage situations where the model needs more data to improve.
And while you're in that planning stage, take a look at software like Reality AI Tools that brings all of this together into a single environment for product development with machine learning and sensors.


