
What is e-AI Translator?
e-AI Translator is a tool that converts learned AI algorithms created using an open source AI framework into C source code dedicated to inference. The latest version of this e-AI Translator V2.3.0 was released on October 4, 2022.
In this blog, I will introduce the enhanced function of V2.3.0, "Speed improvement and RAM usage reduction when using CMSIS_INT8 library". In addition, as a method for further speeding up, I will also introduce the structure of the dataset of the library handled by e-AI Translator, which we would like you to understand. This content can be used in the RA Family and RX Family.
Improved speed and reduced RAM usage when using the CMSIS_INT8 library
The CMSIS_INT8 library is a function implemented in e-AI Translator V2.2.0. Since it uses the built-in DSP/FPU of the Renesas RX/RA family microcontroller products, it is characterized by being able to operate faster than when using the OSS-free C_FP32/C_INT8 library. On the other hand, in V2.2.0, when the CMSIS_INT8 library was selected, it was necessary to allocate a separate work memory for the internal use of the CMSIS_INT8 library, so the required memory amount was doubled at maximum compared to when using the C_FP32/C_INT8 library.
In contrast, e-AI Translator V2.3.0 significantly reduces the required RAM size by placing some of the quantization parameters in ROM. Especially for network structures that use a lot of Convolution, it is now possible to reduce the required RAM size compared to using the C_INT8 library.
I will confirm the effect using the model of ML Commons' MLPerf™ Tiny Inference benchmark, which is the standard benchmark for AI for MCUs.
Table 1. Comparison of inference speed and memory size between e-AI Translator V2.2.0 and V2.3.0
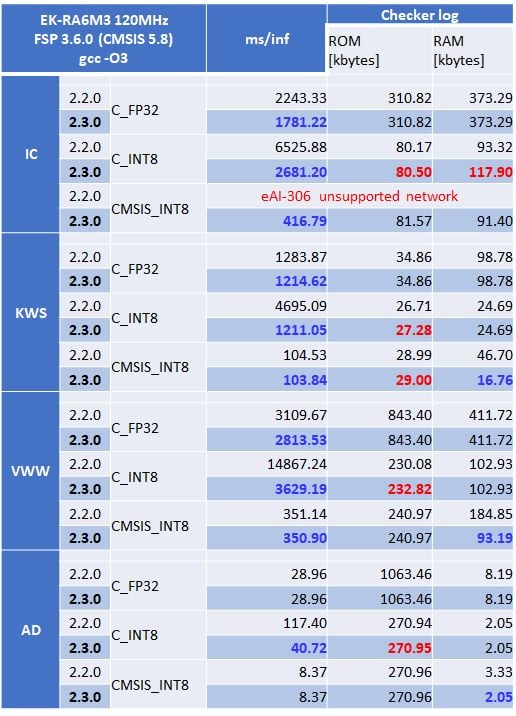
*Blue text: Items improved from V2.2.0 / Red text: Items with increased memory requirements
In MLPerf™ Tiny models, only IC models with ResNet structures have branch structures. e-AI Translator V2.3.0 now supports the branch structure when using the CMSIS_INT8 library.
Let's use Table 1 to compare when using the C_INT8 library and when using the C_FP32 library. The C_INT8 library has a ROM size of 1/4 and a RAM size of 1/2 to 1/3 of the C_FP32 library.
On the other hand, every time one Int8 function calculation is finished, a requantization calculation is performed to keep the next function input value within the range of Int8. As a result, the overall inference time is about 50% slower than when using the C_FP32 library.
In V2.3.0, redundant calculations such as ReLU immediately after Convolution have been deleted. As a result, it is more than 1.5 times faster than V2.2.0. As a result, it has become possible to use more complex AI models at a practical speed on microcontrollers that cannot use the CMSIS_INT8 library due to reasons such as not having a DSP or FPU.
Next, let's compare when using the CMSIS_INT8 library and when using the C_INT8 library. When using the CMSIS_INT8 library, due to the optimization of the data structure performed in V2.3.0, although the ROM size increases slightly, the required RAM size is reduced to the same level as when using the C_INT8 library.
As a result, the inference speed has improved significantly compared to when using the C_FP32 library, and the ROM/RAM size is comparable to when using the C_INT8 library, making it possible to use it as a high-speed and compact AI algorithm. When using TensorFlow Lite's INT8 models, we recommend using the CMSIS_INT8 library.
When using the CMSIS_INT8 library with an RA series microcontroller, use FSP3.5 or higher and FSP3.71 or lower, and add CMSIS/DSP and CMSIS/NN in the FSP Component. If you want to use the CMSIS_INT8 library with RX family microcontrollers, please obtain CMSIS for RX (free) separately. CMSIS for RX is a library that has been modified to use the DSP instructions built into RX series microcontrollers for functions that are often used and have a high execution time reduction effect among the functions of the CMSIS library. For details on how to use it, refer to the e-AI translator user's manual and the CMSIS for RX application note.
Tips for further speedup
Understanding data structure
There are many AI frameworks, but the two main types of data structures are:
- Channel First: Caffe, PyTorch, etc.
- Channel Last: TensorFlow, Keras, etc.
I think it's easier to understand if you look at the 4D shape data structure used in Convolution2D.
- Channel First: [nCHW]
- Channel Lasr: [nHWC]
n: the Number of data (images) in batch C: Channel H: Height W: Width
The e-AI translator assumes Channel First. Image data is often Channel last (color information is last), but the library uses a Channel First data structure with high-speed calculations. Therefore, when converting with the e-AI translator, the input and output of the dnn_compute function, which is an inference function, must be a Channel First format data structure.
On the other hand, the CMSIS_INT8 library adopted from V2.2.0 has a Channel Last data structure. The dnn_compute function of the e-AI translator assumes that the input/output is Channel First, so if you specify the CMSIS_INT8 library for the input/output of 4D shape, the process of converting from nCHW to nHWC is added as follows.
Ex) Conv2D-Conv2D-Conv2DTrasnspose-Conv2DTraspose (CNN AutoEncorder)
Source code of Translator/dnn_compute.c after running e-AI Translator (excerpt)
TsOUT* dnn_compute(TsIN* input_1_int8, TsInt *errorcode)
{
*errorcode = 0;
//Converting the dataformat from NCHW to NHWC;
transpose4d(input_1_int8,dnn_buffer1,layer_shapes.input_1_int8_tr_shape,errorcode);
arm_convolve_s8(*Argument omitted);
:
:
:
sigmoid(*Argument omitted);
//Converting the dataformat from NHWC to NCHW;
transpose4d(dnn_buffer1,dnn_buffer2,layer_shapes.Identity_int8_tr_shape,errorcode);
return(dnn_buffer2);
}
How to further speed up when CMSIS_INT8 is specified
The Transpose part is just transforming the data structure. Rewrite dnn_compute.c so that this part is not transposed. You can speed it up by using the dnn_compute input data in Channel Last format.
The specific steps are as follows. The Transpose function has the following arguments.
- First argument: Transpose target array
- Second argument: array after Transpose
- Third argument: shape of array to be transposed
- Fourth argument: errorcode (presence or absence of malloc error)
First, check the variable name used in the first argument. Check the variable name used for the second argument of Transpose in the function next to the Transpose function.
TsOUT* dnn_compute(TsIN* input_1_int8, TsInt *errorcode)
{
*errorcode = 0;
//Converting the dataformat from NCHW to NHWC;
transpose4d(input_1_int8,dnn_buffer1,layer_shapes.input_1_int8_tr_shape,errorcode);
arm_convolve_s8(&cr_buffer,&layer_shapes.model_conv2d_Relu_shape.conv_params,&model_conv2d_Relu_multiplier,&layer_shapes.model_conv2d_Relu_shape.input_dims,dnn_buffer1,&layer_shapes.model_conv2d_Relu_shape.filter_dims,model_conv2d_Relu_weights,&layer_shapes.model_conv2d_Relu_shape.bias_dims,model_conv2d_Relu_biases,&layer_shapes.model_conv2d_Relu_shape.output_dims,dnn_buffer2);
:
:
:
sigmoid(*Argument omitted);
//Converting the dataformat from NHWC to NCHW;
transpose4d(dnn_buffer1,dnn_buffer2,layer_shapes.Identity_int8_tr_shape,errorcode);
return(dnn_buffer2);
}
If you find a variable name with the same name as the second argument, replace it with the variable name of the first argument and comment out Transpose.
TsOUT* dnn_compute(TsIN* input_1_int8, TsInt *errorcode)
{
*errorcode = 0;
//Converting the dataformat from NCHW to NHWC;
//transpose4d(input_1_int8,dnn_buffer1,layer_shapes.input_1_int8_tr_shape,errorcode);
arm_convolve_s8(&cr_buffer,&layer_shapes.model_conv2d_Relu_shape.conv_params,&model_conv2d_Relu_multiplier,&layer_shapes.model_conv2d_Relu_shape.input_dims,input_1_int8,&layer_shapes.model_conv2d_Relu_shape.filter_dims,model_conv2d_Relu_weights,&layer_shapes.model_conv2d_Relu_shape.bias_dims,model_conv2d_Relu_biases,&layer_shapes.model_conv2d_Relu_shape.output_dims,dnn_buffer2);
:
:
:
sigmoid(dnn_buffer1,Identity_int8_multiplier,Identity_int8_offset,dnn_buffer1,layer_shapes.Identity_int8_shape,errorcode);
//Converting the dataformat from NHWC to NCHW;
//transpose4d(dnn_buffer1,dnn_buffer2,layer_shapes.Identity_int8_tr_shape,errorcode);
return(dnn_buffer1);
}
With this change, when CMSIS_INT8 is specified, the input/output data of the inference function can be handled in Channel Last format. It is a method that can be used without changing the data format of Channel Last of TensorFlow Lite and can be expected to speed up. Please take advantage of it.
How to use FSP 4.1 (CMSIS V5.9)
The CMSIS V5.9 (CMSIS NN V3.1) library has been modified to utilize the following parameters of Convolution.
cmsis_nn_tile cmsis_nn_conv_params::dilation
e-AI Translator V2.3.0 outputs this value to Translator/layer_shapes.h as 0. Therefore, if the CNSIS V5.9 library is used as is, part of the Convolution calculation will be skipped and incorrect inference results will be output.
If you want to use Translator/layer_shapes.h output by e-AI Translator V2.2.0/2.3.0 with CMSIS NN V3.1 included in CMSIS V5.9, please rewrite the value of layer_shapes.h in the following procedure.
Find lines starting with conv, dconv in the shapes structure described in Translator/layer_shapes.h.
struct shapes{
TsInt input_1_tr_shape[5];
conv functional_1_activation_Relu_shape;
dconv functional_1_activation_1_Relu_shape;
:
:
fc functional_1_dense_BiasAdd_shape;
TsInt Identity_shape;
};
Check the line that sets the value of the variable using this structure. The value is set in one line for each variable name.
struct shapes layer_shapes ={
// input_1_tr_shape[5];
{1,1,49,10,1},
// functional_1_activation_Relu_shape;
{1,49,10,1,64,10,4,1,1,25,5,64,1,1,1,64,-83,-128,2,2,1,4,0,0,-128,127},
// functional_1_activation_1_Relu_shape;
{1,25,5,64,1,3,3,64,1,25,5,64,1,1,1,64,128,-128,1,1,1,1,1,0,0,-128,127},
:
:
{1,64,64,1,64,1,1,12,1,1,1,12,1,1,1,12,128,0,14,-128,127},
12
};
Among the conv and dconv parameter settings, cmsis_nn_conv_params::dilation corresponds to the 3rd and 4th values from the back. Currently 0 is being output, so please change this value to 1. With this fix, it will work properly with a library that recognizes dilation in CMSIS NN V3.1 or later.
struct shapes layer_shapes ={
// input_1_tr_shape[5];
{1,1,49,10,1},
// functional_1_activation_Relu_shape;
{1,49,10,1,64,10,4,1,1,25,5,64,1,1,1,64,-83,-128,2,2,1,4,1,1,-128,127},
// functional_1_activation_1_Relu_shape;
{1,25,5,64,1,3,3,64,1,25,5,64,1,1,1,64,128,-128,1,1,1,1,1,1,1,-128,127},
:
:
{1,64,64,1,64,1,1,12,1,1,1,12,1,1,1,12,128,0,14,-128,127},
12
};
Tool download link
Previous blogs
- More than 10 Times Faster AI Inference for RX and RA Families Released e-AI Translator V2.2.0 for Arm CMSIS Library
- Contribute to the Reduction of ROM/RAM Usage by 8-Bit Quantization Released e-AI Translator v2.1.0 for TensorFlow Lite
