The Stream Transpose® (STP) engine is a reconfigurable processor (DRP: Dynamically Reconfigurable Processor) core that combines the flexibility of software and the speed of hardware. The firmware defining processing can be reconfigured in an instant, allowing an almost infinite variety of functions to be integrated into a system. A 40nm process is currently available for ASIC.
High-Performance STP Engine Structure
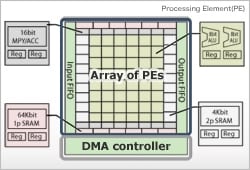
The STP engine has an array of processing elements (DRP) + DMA controller structure.
Data transfer (DMA) is dedicated and is divided from processing (array of processing elements). This helps to improve performance and mounting area efficiency, reducing the CPU workload and improving overall system performance.
An array of processing elements (PEs) consists of processing elements and memory. Memory and a multiplier encircle an array of PEs. With an STP engine, processing is performed in parallel using multiple computing units and memory, realizing higher performance.
Efficient Data Transfer
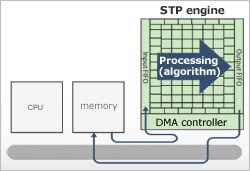
The DMA performs efficient memory-to-memory data transfer. Data transfer overhead is reduced by operating the DMA and the programmable computing unit array simultaneously.
A verification model of the STP engine is included in the design tools. The issuing of access instructions to the DMA and the carrying out of algorithms by a programmable computing unit array can be described in the same C program, so this mechanism is easy to optimize.
In addition, since the functionality assigned to the STP engine and the CPU can be changed by software, a flexible system that meets the customer's requirement specifications can be built.
The Hardware Switching Capability of the DRP
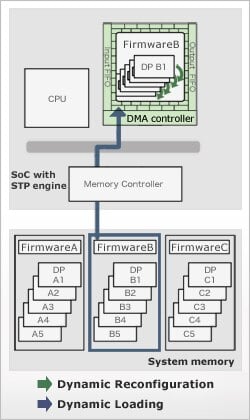
Dynamic Reconfiguration

It extends the effective logic region by dynamically reconfiguring and switching by time sharing the circuits mounted in the limited area of the programmable computing unit array area. There are a maximum of 64 contexts (for an IP core for ASIC; for XBridge there are 32 contexts) of data path (DP) information stored in the STP engine. DP switching, which takes less than 1ns, and processing are performed in one clock.
Dynamic Loading
During execution, another firmware is additionally read from external memory, and the hardware is changed to correspond to a completely different function. A large application, which would not fit on a chip, is performed using time sharing. The switching time is several hundred μs.