
In the first two articles, we respectively introduced how to use RZ/A2M and its unique Dynamically Reconfigurable Processor (DRP) technology to realize target object detection and tracking in smart factories and how to achieve rapid detection of two-dimensional code encoding types. Now, let's take a look at the combination of RZ/A2M's DRP and embedded AI to realize masked face detection.
In the example, we connect the Sony IMX219 CMOS sensor through the MIPI interface, input a 1280x720 resolution image, use DRP in RZ/A2M to perform Simple ISP processing and image scaling processing on the input image, and then run a light and efficient masked face detection model. It can achieve a detection speed of 30FPS in the face detection mode, and a detection speed of 20FPS in the mode of distinguishing whether to wear a mask. Let's take a look at how it is implemented.

The following figure shows the data processing flow:
The processing of the portion shown in blue is realized by DRP hardware acceleration, and the Simple ISP library converts the Bayer format data of the CMOS sensor into gray-scale data and counts the average brightness of three preset areas in a frame of the image to adjust the automatic exposure parameters.
The second DRP library implements image scaling, compressing the 1280x720 resolution grayscale image into a 640x360 size image, which will greatly improve the face detection speed.
The green part in the picture is a light mask and face detection model run by the Cortex-A9 processor, which is used to calibrate whether the current frame has a human face and whether it has a mask.
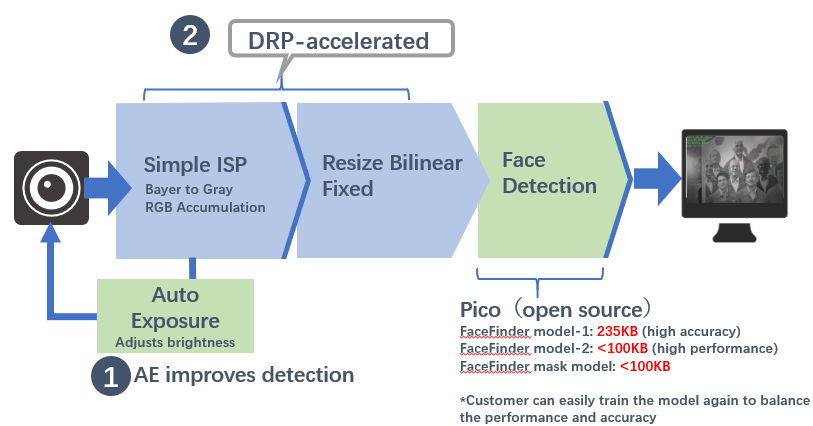
In this example, we will not rely on external RAM and only use RZ/A2M's 4MB on-chip high-speed RAM.
Step 1
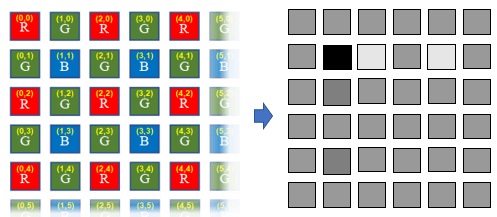
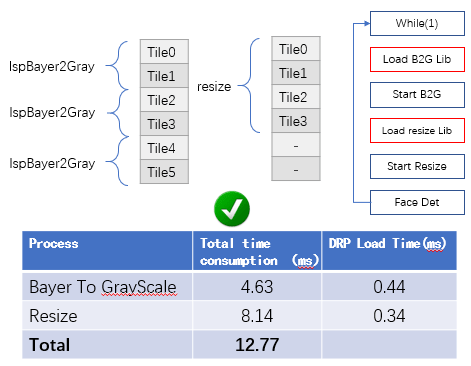
Since face detection only needs to use grayscale images, we need to convert the Bayer format image of the CMOS sensor into a grayscale image. At this time, we load a simple_isp_2_tiles DRP library. This DRP library needs to have the following characteristics:
- Occupies 2 tiles of DRP hardware resources
- Realize Bayer to grayscale
- Accumulate the brightness values of all pixels in 3 independent areas
- Support multi-tile parallel processing
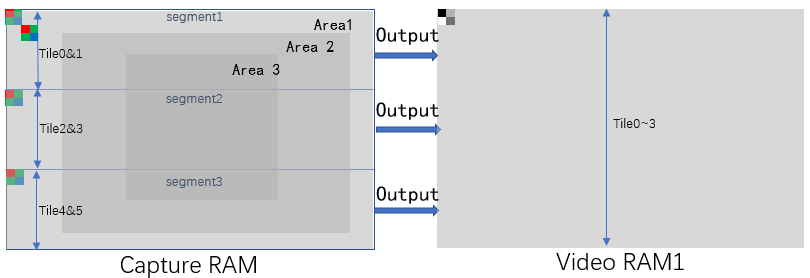
Since this library features multi-tile parallelized (segmented) processing, we can load it into 3 sets of DRP tiles. Among them, the simple_isp_2_tiles library of Tile 0 and 1 handles the top 1/3 of the image, the simple_isp_2_tiles library of Tiles 2 and 3 handles the middle 1/3 of the image, and the simple_isp_2_tiles library of Tile 4 and 5 handles the bottom 1/3 of the image. These three parts of images are processed in parallel at the same time, which increases the processing speed by 3 times.
Because the DRP library provides a very convenient API interface, the above functions can be realized by simple programming operations.

Users can decide how to load the DRP library according to the Number of tiles and Segmented Processing attributes in the application documentation of the DRP library.
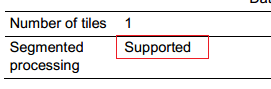
- Number of tiles: Indicates that the DRP library needs to occupy how many hardware tiles
- Segmented processing: Indicates that the DRP task can be split into multiple tiles for parallel execution
There are 11 ways to place the DRP library in the Tile. You can choose which loading method to use according to the Number of tiles and Segmented attributes of the DRP library in a flexible way. Below are some examples:
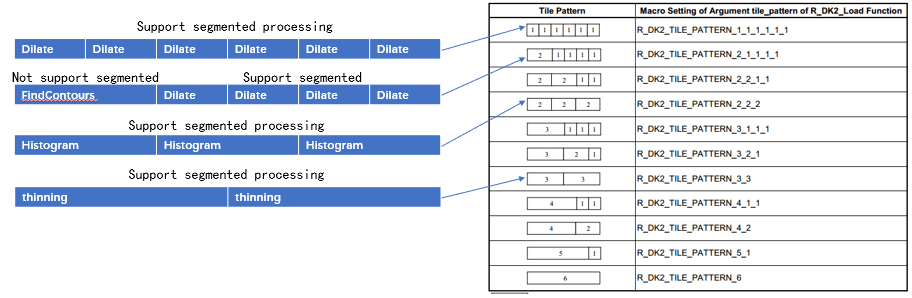
Step 2
After getting a frame of a grayscale image, we load a DRP library by resize bilinear_fixed to zoom this frame of image. Key features of the DRP library:
- Input 8bpp grayscale image
- Support ⅛ ¼ ½ 1x 2x 4x 8x 16x fixed zoom ratio
- Separate control of horizontal and vertical scaling
- Input width range 128~1280, input height range 8~960
- Occupies 4 tiles hardware resources without supporting segmented
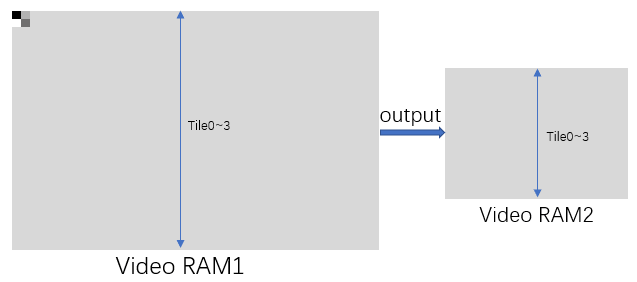
After processing Step 2, we read the grayscale image from Video RAM1, reduce the width and height to the original ½, and write the image to Video RAM2 for the next face detection.
The execution time of these two steps is about 4.6ms and 8.2ms. The parallel processing and the loading speed of the DRP library of less than 1ms have greatly optimized the execution speed of image preprocessing before face recognition.
Step 3
We used a light open source face recognition algorithm https://github.com/nenadmarkus/pico
A data set of masked faces was added based on it, and the new data set was trained. After testing, its recognition speed and recognition accuracy are relatively ideal.
First, you need to prepare a data set, which can be directly trained through the data set in our sample package or downloaded from the network.

This data set contains 7092 face pictures and 4283 face mask pictures, and the key features of the face in the pictures are calibrated.


The AI model is not a commonly used neuron network model, but a decision tree model, which has the characteristics of fast execution, and its model size is only tens of KB to 200KB.
The following are the more commonly used algorithms in the AI field:

A decision tree is a non-parametric supervised learning model that allows you to follow the results of the tree-like decision branch step-by-step from the root node to the top leaf node, thereby predicting the target value based on the result of the top leaf node. It is often used for target classification and regression
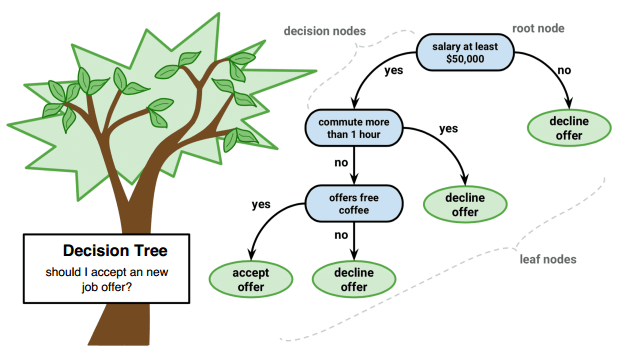
Resource: Machine Learning Notes by Heart of Machine
In the face detection process, we use a sliding window to scan the image generated in Step 2 step-by-step, first use the smallest sliding window, and then gradually increase the size of the window. Use the decision tree model to detect whether there is a face in each sliding window.
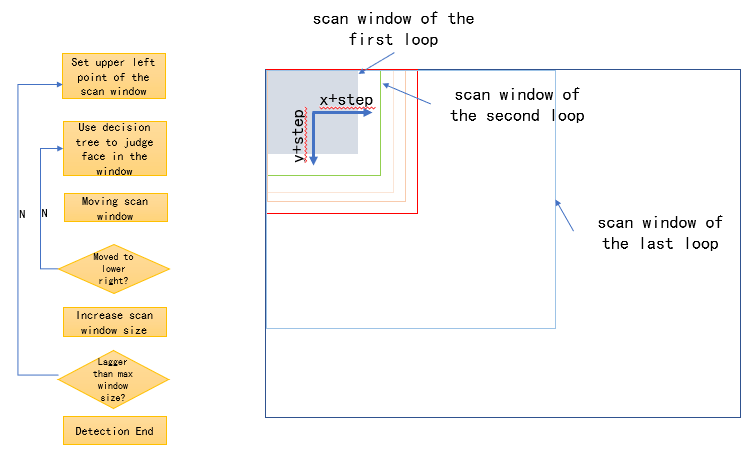
The following is the configuration of some key parameters, we can balance between detection accuracy and performance through parameter adjustment.

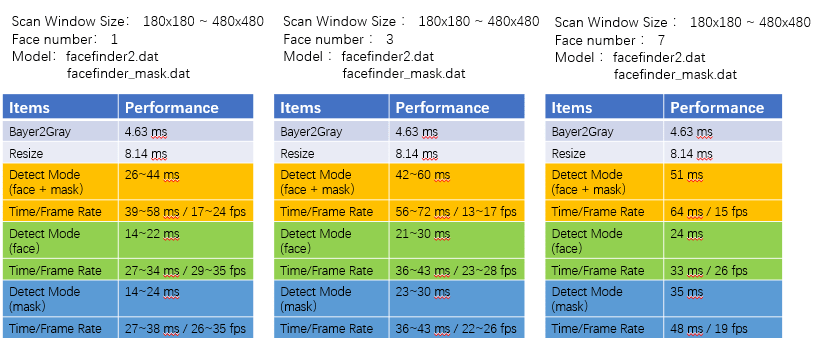
The following is a 1280x720 resolution input, which detects 1 face, 3 faces and 7 faces in the screen respectively. In the mask face mode, the detection speed can be above 15FPS.
The following video is the test result of face detection for fast switching images. It can be seen that RZ/A2M can capture the face in the image in real time after DRP acceleration and running light and efficient AI algorithm.
