
データ完全性と規制
データというものは、数値的フォーマットで表された、個々に独立した事実、統計、あるいは情報の組み合わせとして考えられます。データとその管理の重要性は、コンピュータサイエンスの誕生とともに認識されるようになりました。ですがもともとは、データの変換、保管、そして転送に重点を置いていたのです。しかし近年、これまでになかった情報爆発が起こっています。これは、スマートフォン、インテリジェントセンサー、コネクテッドカー、そのほかにも私たちの周りにある様々なデジタルデバイスなどの増加が関係しているといえます。
増え続ける膨大なデータ量は、重複性を減らし、正確でタイムリーな結果を保証して、データの質を確かなものにしながら管理する必要性を生みました。分析において膨大な情報量にアクセスし保管する方法は、ずっと存在してきました。しかし、3つの「V」 を基にしたビッグデータのコンセプトが2000年代初めに台頭します。その3つとは、Volume(ボリューム)、Velocity(速度)、Variety(多様性)です。そもそもビッグデータは、意思決定を改善するより良い知見のために分析されるまで、さほど有益なものではありません。つまり収集されたデータは、問題解決、そして新しい利益源と経済成長を果たすのに使われるときのみしか意味がないのです。そして、ここでこそ“データサイエンス”が鍵となってくる部分です。データ内の目に見えないパターンを検知し、意味のある情報を導き出し、最良なビジネスの意思を行うためにモダンなツールと技術を使う必要があるからです。
データサイエンスとは何か
データサイエンスとは、さまざまな科学的メソッド、アルゴリズム、方法を使い、増加し続けるデータから知見を抽出する統合型アプローチを意味する用語です。これは、未処理データ内から隠れたパターンを認識するソフトウェアによって実行されます。これらの貴重な知見は、ビジネスが抱える苦境を実行可能な解決策に変え、組織的な意思決定をサポートするのに使われます。
ビジネスはデータサイエンスをどう使えるか?
従来のビジネスインテリジェンスツールは、非構造化データという巨大なプールを処理するのに構造化されていません。ここで、データサイエンスが重大な役割を担います。なぜなら、多数の相関的フィールド内で、あらゆるソースから届く巨大なデータを分析、整理、ふるいわけするのに、高度なツールを有効利用するからです。例えば、マーケティング分野において、顧客の年齢、性別、場所、行動といった基本的情報を調査することは、より最適化されたキャンペーンを作りだすのに役立ちます。消費者が商品を購入するのか、それとも放棄するのか傾向を評価するのに閲覧、購入履歴を参考にして、より正確なリコメンデーションを表示します。同様に銀行サービス分野では、普段とは違った消費者行動を検出することは、詐欺を探知し、発見するのに役立ちます。またヘルスケア分野では、患者の診療録を精査、評価することで、病気発症の可能性などを示せるかもしれません。
予測メンテナンスの力を活用し、工場設備に埋め込まれたスマートセンサーは、ダウンタイムの低減、そして収益の損失を回避するのに役立つ、最適なオペレーション方法に関するデータを収集することができます。潜在的な故障問題を予想して取り掛かれば、工場はピーク効率で稼働できるのです。
データマイニングとKDD
“データマイニング”という用語は、しばしばKDD(データベースからの知識発見)という言葉と互換的に使われます。現在、ありとあらゆる人々のレベルでデータに基づいて動かされている世界が広がっています。しかし、データというものは、真価に近づく分析をすることができるとき、重要になってくるのです。
多くの産業が膨大なデータ量を蓄積していますが、データモデルをグラフ化、チャート化、トレンド化するメカニズムなしに、純粋なデータそのもの自体はほとんど意味をなしません。蓄積され続けるデータ量とスピードのせいで、従来のメカニズムを利用することは難しくあります。それゆえ、より経済学的に、そして科学的に、データサイエンスを使った分析力を向上させることが必要となってきています。そうすることによってようやく、私たちが今必要としている巨大なデータ量を処理し、より良いポジションに立てることができるのです。
下記のダイアグラムは、データ管理を助けるさまざまなツールと方法の関係性を示しています。
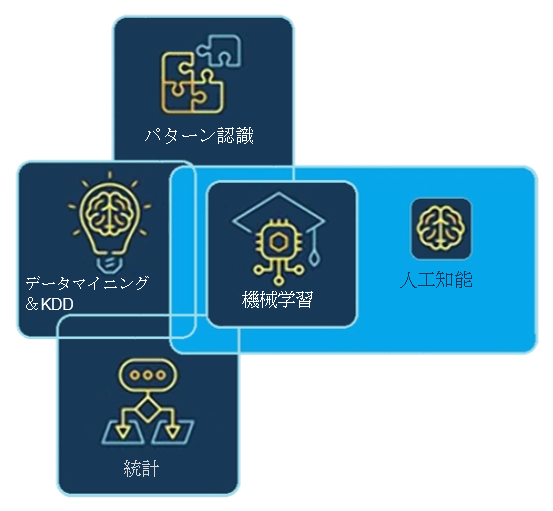
パターン認識
パターン認識はその内部のパターンを識別して、インバウンドデータを探ります。ここにはデータのタイプと構成に基づいて活用される、さまざまなパターン認識方法があります。一般的に、データパターンは調査型パターン認識で識別され、検出パターンは記述型パターン認識で識別されます。これは、はっきりした特徴を認識するのに物体を精査し、データ多様性からそこにマッチングがあるのか違いがあるのかどうかを判断するために、すでに知っているパターンとこれらの特徴を比較することも含みます。
統計
統計は、複雑で方法論的アプローチを必要とする問題に対処するのに重大な役割を担っています。これは特に、懐疑要素があるなかで、一か八かの意思決定がなされる場合に役立ちます。分析によって湧き上がった疑問に対して、たっぷりの自信つきでスマートな答えを与えてくれるのです。
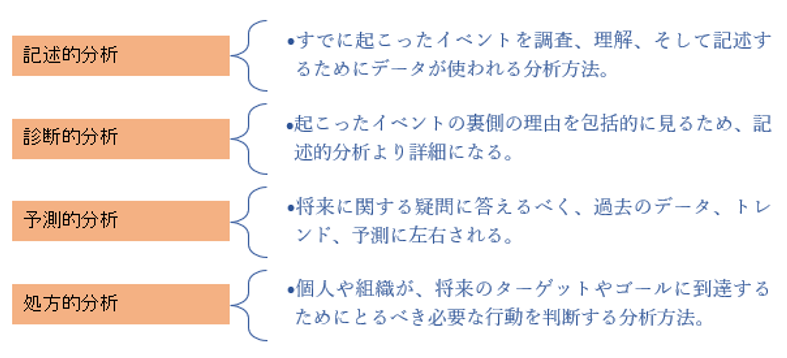
分析
データ分析は疑問に答え、知見を獲得し、トレンドを識別するためのデータ調査の処理と実行に関係しています。実行される分析タイプによって、さまざまなツール、技術、フレームワークをミックスして行われます。これは以下のように大きく4つのタイプに分かれます:
機械学習
機械学習は、過度にプログラム化されずに、自動タスクを実行するためのモデルによって決まる人工知能の一種です。ユーザーが過去のデータに基づいた予測や決定を行えるよう、統計型技術やアルゴリズムを使っています。データ科学者は、会社が保持しているデータを調べるため、機械学習や人工知能といった技術を活用します。これはまた、会社が今後起こることを正確に分析することを可能にし、その結果、将来いいインパクトを与えることができるのです。
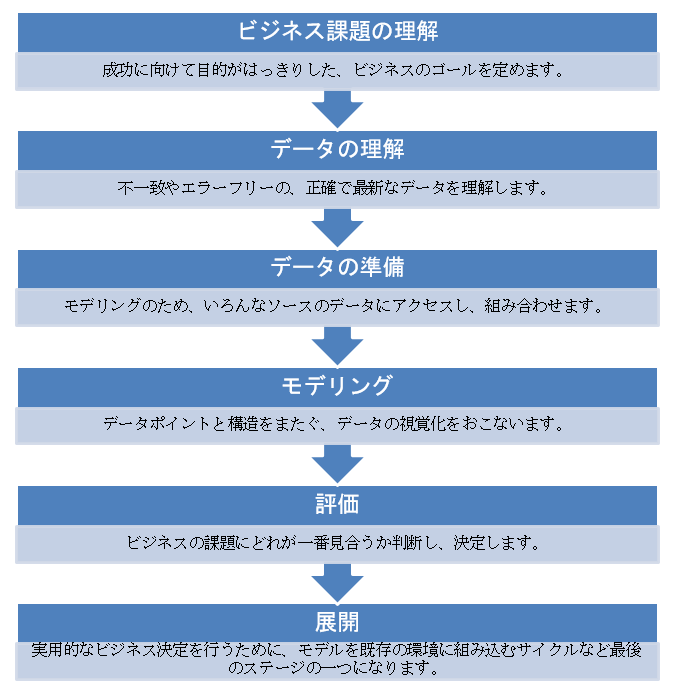
データサイエンスのプロセス
データマイニングのための業界横断型標準プロセスを表すCRISP-DMとは、データサイエンスライフサイクルを理解するためのプロセスモデルです。データサイエンスプロジェクトを計画、組織、そして実装するのに役立つ足組みになります。これには次のステップを含みます:
批判的思考が機械学習アルゴリズムと出会うと、データサイエンスはより良い知見を見出し、効率的な努力を促し、予測を立ててくれます。ここでのゴールは、ビジネスがより進歩的な意思決定を行い、革新的な製品とサービスを作るために、データサイエンスから利益を得ることなのです。