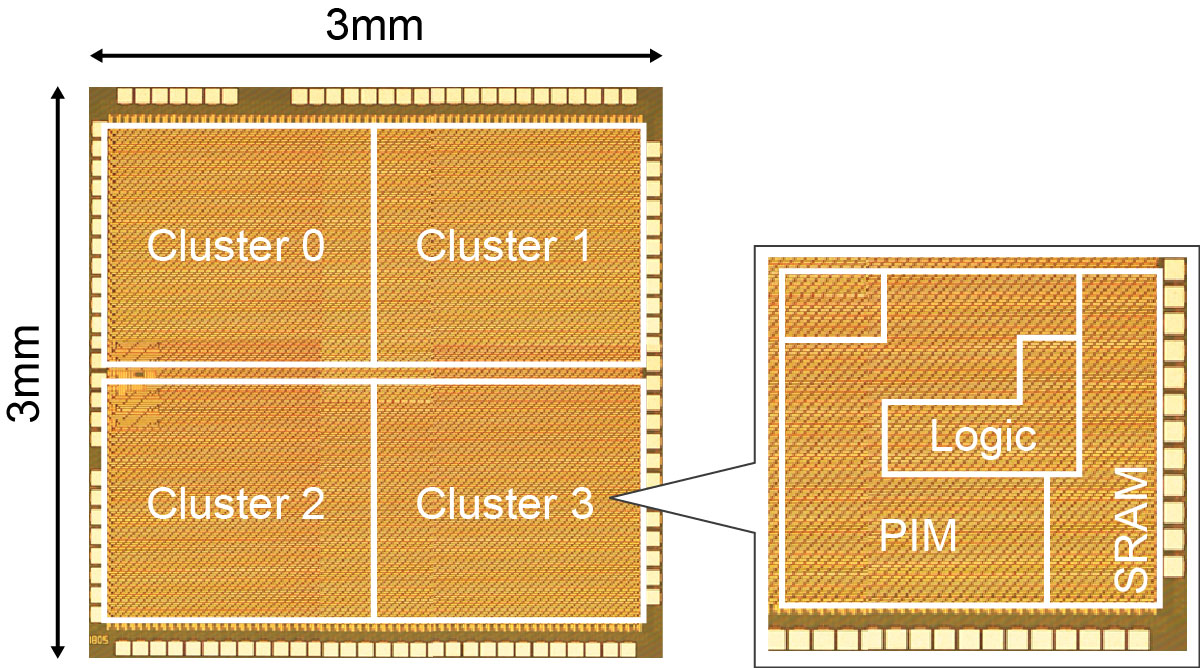
ルネサス エレクトロニクス株式会社(代表取締役社長兼CEO:呉 文精、以下ルネサス)は、このたび、エンドポイントのインテリジェント化を加速するルネサスの組み込みAI(e-AI)の次世代ソリューション展開に向けて、低消費電力で高速にCNN(Convolutional Neural Network)処理を実現するAIアクセラレータを開発し、本アクセラレータを搭載したテストチップにて、世界最高クラスの8.8 TOPS/W(注1)の電力効率を実証しました。本アクセラレータは、メモリ回路内でメモリデータの読み出し中に積和演算まで行うという、AI技術の一つとして近年注目されるProcessing-in-Memory(PIM)アーキテクチャをベースにしています。ルネサスは今回、本アクセラレータの実現のために、(1)大規模CNN演算を可能にする3値(-1, 0, 1)SRAM構造のPIM技術を開発、(2)コンパレータを応用し、低消費電力でメモリデータの読み出しが可能なSRAM回路を開発、また、(3)製造プロセスのばらつきによる演算誤差を回避する技術も開発しました。これらにより、ディープラーニング処理におけるメモリアクセス時間の短縮と、積和演算の消費電力低減を両立し、手書き文字認識(MNIST)で評価した結果、99%以上の認識率を保ちつつ、世界最高クラスの電力効率も達成しました。
ルネサスは今回の成果を、2019年6月9日から14日まで京都で開催されている「2019 VLSI技術/回路シンポジウム(2019 Symposia on VLSI Technology and Circuits)」にて、6月13日に発表しました。また、期間中に開催されたデモセッションでは、小型電池にて駆動した本テストチップにマイコンやカメラなどの周辺機器を接続したAIモジュールの試作品と、開発ツールの試作品を出展し、リアルタイムな画像認識の実演も行いました。
従来、PIMアーキテクチャは「0」か「1」のデータしか扱えない2値(0, 1)SRAM構造のため、1ビット演算では大規模CNN演算に十分な演算精度を達成できませんでした。また、製造プロセスのばらつきも演算の信頼性を低下させる要因であり、対策が必要です。ルネサスは今回、これらの課題を解決する新たな技術を開発し、将来の革新的AIチップを実現する先進的な技術の一つとして、性能と電力効率の両立が求められるロボットやウェアラブル機器などの次世代e-AIソリューションに適用していきます。
このたび開発した新技術は以下の通りです。
(1)必要な演算精度に応じてビット数を調整する、3値(-1, 0, 1)SRAM構造のPIM
今回新たに開発した、3値(-1, 0, 1)SRAM構造のPIMアーキテクチャは、3値メモリと簡単なデジタル演算ブロックの組み合わせにより、ハードウェアの増加や演算誤差の増加を最小限に抑えつつ、必要精度に応じて演算ビット数を1.5ビット(3値)や4ビット演算などに切り替えが可能です。ユーザごとに異なる演算規模と精度要求に対応可能なため、演算精度と消費電力のバランスを最適化できます。
(2)コンパレータとレプリカセルを組み合わせた、高精度で低消費なメモリデータ読み出し回路
PIMアーキテクチャを適用した場合、メモリデータはSRAM構造におけるビット線電流の値を検出することで読み出します。高精度なビット線電流の検出にはアナログデジタル変換器(A/Dコンバータ)を用いるのが有効ですが、この場合、高い消費電力とチップ面積の増大が課題となります。今回、A/Dコンバータを用いず、コンパレータ(1ビットセンスアンプ)と電流値を自由に制御できるレプリカセルを組み合わせ、高精度なメモリデータ読出し回路を開発しました。さらに、ニューラルネットワークの動作では活性化しているノード(ニューロン)は1%程度のごく一部であるという特性を活かし、非活性化ノードに対しては読み出し回路自体の動作を停止させることで、さらなる低電力化を実現しました。
(3)製造プロセスのばらつきによる演算誤差抑制、ばらつき回避技術
PIMは大幅な低電力化が可能な反面、製造プロセスのばらつきによる演算誤差が発生する課題があります。これは、製造プロセスのばらつきによって、SRAM構造におけるビット線電流の値に誤差が生じ、結果、メモリデータの読み出しに誤差が生じるからです。そこで、チップ内に多数のSRAM演算回路ブロックを敷き詰め、製造プロセスのばらつきが小さいブロックで演算する方式を開発しました。前述したように、活性化しているノード(ニューロン)はごく一部である特性を利用し、製造プロセスばらつきの小さいSRAM演算回路ブロックに選択的に活性化ニューロンを配置し、演算します。これにより、ほとんど無視できるレベルまで演算誤差を低減できます。
ルネサスは、2015年の組み込みAI(e-AI)のコンセプトを発表以来、e-AIソリューションの開発を推進しています。ルネサスはe-AIの実効性能と実現する用途に基づき、「クラス」を定義しており、信号波形データの正常・異常の判断ができるClass-1、リアルタイムな画像処理による正常・異常の判断ができるClass-2(100 GOPS/W級)、リアルタイムな認知判断ができるClass-3(1 TOPS/W級)、さらにエンドポイントでの追加学習が可能なClass-4(10 TOPS/W級)のそれぞれのクラスに対し、e-AIソリューションの開発を進めています。すでに、2017年にはe-AI開発環境の提供を開始、2018年には、AIアクセラレータとして独自の技術であるDRP(Dynamically Reconfigurable Processor)を搭載したRZ/A2Mを発表し、Class-2までを市場に提供しています。Class-3の実現に向けては、さらにDRPの演算性能を強化し、そして今回発表した新技術は、低消費電力と演算性能を兼ね合わせた将来のClass-4を実現する先進技術の一つとして開発したものです。ルネサスは今後も、IoTにおけるエッジ、エンドポイントでのAIを適用したインテリジェント化を通して、スマート社会の実現に貢献してまいります。
以 上
(注1)TOPS/Wは、Tera Operations per Second per Wattの略であり、1Wの電力で可能な演算回数を表す。8.8 TOPS/W は、1Wの電力で8.8兆回の演算が可能な性能
*本リリース中の製品名やサービス名は全てそれぞれの所有者に属する商標または登録商標です。
ニュースリリースに掲載されている情報(製品価格、仕様等を含む)は、発表日現在の情報です。 その後予告なしに変更されることがございますので、あらかじめご承知ください。