
We're an AI company, so people always ask about our algorithms. If we could get a dollar for every time we're asked about which flavor of machine learning we use –convolutional neural nets, K-means, or whatever – we would never need another dollar of VC investment ever again.
But the truth is that algorithms are not the most important thing for building AI solutions — data is. Algorithms aren't even #2. People in the trenches of machine learning know that once you have the data, It's really all about "features."
In machine learning parlance, features are the specific variables that are used as input to an algorithm. Features can be selections of raw values from input data, or can be values derived from that data. With the right features, almost any machine learning algorithm will find what you're looking for. Without good features, none will. And that's especially true for real-world problems where data comes with lots of inherent noise and variation.
With the right features, almost any machine learning algorithm will find what you're looking for. Without good features, none will.
My colleague Jeff (the other Reality AI co-founder) likes to use this example: Suppose I'm trying to detect when my wife comes home. I'll take a sensor, point it at the doorway and collect data. To use machine learning on that data, I'll need to identify a set of features that help distinguish my wife from anything else that the sensor might see. What would be the best feature to use? One that indicates, "There she is!" It would be perfect — one bit with complete predictive power. The machine learning task would be rendered trivial.
If only we could figure out how to compute better features directly from the underlying data… Deep Learning accomplishes this trick with layers of convolutional neural nets, but that carries a great deal of computational overhead. There are other ways.
At Renesas, where our tools create classifiers and detectors based on high sample rate signal inputs (accelerometry, vibration, sound, electrical signals, etc) that often have high levels of noise and natural variation, we focus on discovering features that deliver the greatest predictive power with the lowest computational overhead. Our tools follow a mathematical process for discovering optimized features from the data before worrying about the particulars of algorithms that will make decisions with those features. The closer our tools get to perfect features, the better end results become. We need less data, useless training time, are more accurate, and require less processing power. It's a very powerful method.
Features for Signal Classification
For an example, let's look at feature selection in high-sample rate (50Hz on up) IoT signal data, like vibration or sound. In the signal processing world, the engineer's go-to for feature selection is usually frequency analysis. The usual approach to machine learning on this kind of data would be to take a signal input, run a Fast Fourier Transform (FFT) on it, and consider the peaks in those frequency coefficients as inputs for a neural network or some other algorithm.
Why this approach? Probably because it's convenient, since all the tools these engineers use support it. Probably because they understand it, since everyone learns the FFT in engineering school. And probably because it's easy to explain, since the results are easily relatable back to the underlying physics. But the FFT rarely provides an optimal feature set, and it often blurs important time information that could be extremely useful for classification or detection in the underlying signals.
Take for example this early test comparing our optimized features to the FFT on a moderately complex, noisy group of signals. In the first graph below we show a time-frequency plot of FFT results on this particular signal input (this type of plot is called a spectrogram). The vertical axis is frequency, and the horizontal axis is time, over which the FFT is repeatedly computed for a specified window on the streaming signal. The colors are a heat-map, with the warmer colors indicating more energy in that particular frequency range.
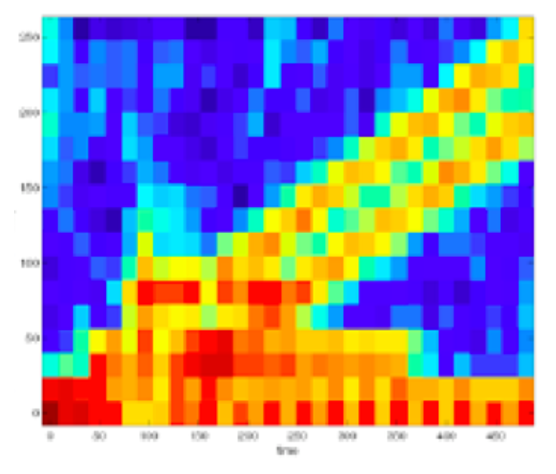
Compare that chart to one showing optimized features for this particular classification problem generated using our methods. On this plot you can see what is happening with much greater resolution, and the facts become much easier to visualize. Looking at this chart it's crystal clear that the underlying signal consists of a multi-tone low background hum accompanied by a series of escalating chirps, with a couple of other transient things going on. The information is de-blurred, noise is suppressed, and you don't need to be a signal processing engineer to understand that the detection problem has just been made a whole lot easier.

There's another key benefit to optimizing features from the get go – the resulting classifier will be significantly more computationally efficient. Why is that important? It may not be if you have unlimited, free computing power at your disposal. But if you are looking to minimize processing charges, or are trying to embed your solution on the cheapest possible hardware target, it is critical. For embedded solutions, memory and clock cycles are likely to be your most precious resources, and spending time to get the features right is your best way to conserve them.
Deep Learning and Feature Discovery
At Renesas, we have our own methods for discovering optimized features in signal data (read more about our technology), but ours are not the only way.
As mentioned above, Deep Learning (DL) also discovers features, though they are rarely optimized. Still, DL approaches have been very successful with certain kinds of problems using signal data, including object recognition in images and speech recognition in sound. It can be a highly effective approach for a wide range of problems, but DL requires a great deal of training data, is not very computationally efficient, and can be difficult for a non-expert to use. There is often a sensitive dependence of classifier accuracy on a large number of configuration parameters, leading many of those who work with DL to focus heavily on tweaking previously used networks rather than focusing on finding the best features for each new problem. Learning happens "automatically", so why worry about it?
My co-founder Jeff (the mathematician) explains that DL is basically "a generalized non-linear function mapping – cool mathematics but with a ridiculously slow convergence rate compared to almost any other method." Our approach, on the other hand, is tuned to signals but delivers much faster convergence with less data. On applications for which Realty AI is a good fit, this kind of approach will be orders of magnitude more efficient than DL.
The very public successes of Deep Learning in products like Apple's Siri, the Amazon Echo, and the image tagging features available on Google and Facebook have led the community to over-focus a little on the algorithm side of things. There has been a tremendous amount of exciting innovation in ML algorithms in and around Deep Learning. But let's not forget the fundamentals.
It's really all about the features.
