Accelerator type DRP (STP: Stream Transpose®) accelerates processing when CPU processing capability is lacking. Data transfer can be performed effectively as the DMA controller is directly connected to the DRP core. As it is possible to rewrite the firmware that defines the processing in a moment, almost infinite functions can be equipped in the system. Currently, 16nm, 28nm and 40nm process IP cores are supported.
High Performance Accelerator Type DRP Structure
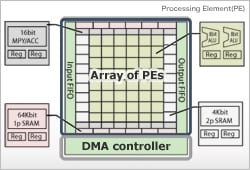
Accelerator type DRP has a structure consisting of a programmable operation device array and a DMA controller.
Data transfer (DMA) is isolated from the processing (programmable operation device array) and made exclusive for data transfer. Thus, this improves the performance and mounting efficiency, reducing CPU load and realizing improved overall system performance.
The programmable operation device array is comprised of an operation device and memory, with the layout of memory and multipliers surrounding an 8- or 16-bit operation device (ALU) array. Accelerator type DRP realizes higher performance by carrying out the processing in parallel using many operation devices and memories.
Efficient Data Transfer
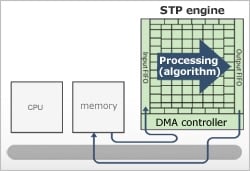
Data transfer between memories is efficiently performed by the enhanced function DMA. By running the DMA and the programmable operation device array at the same time, data transfer overhead is reduced.
A verification model for accelerator type DRP is incorporated into the design tool. Access instruction issuing for the DMA and the algorithm executed in the programmable operation device array can be handled by the same C program, so it is easy to optimize.
Also, function allotment between accelerator type DRP and the CPU is changeable by software, so a flexible system that meets the required specifications can be constructed.
DRP Hardware Switching Capability
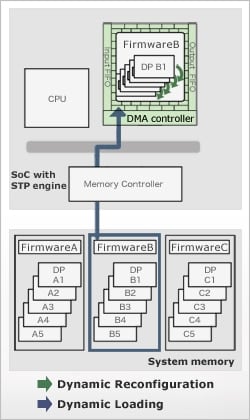
Dynamic Reconfiguration

Up to 64 pieces (in case of a 40nm core for ASIC) of data path (DP) information can be stored. You can dynamically reconfigure and change the circuit implemented in the limited area of the programmable operation device array by time sharing to expand the effective logic area. The processing is executed by switching DP in 0 clock (less than 1ns).
Dynamic Loading
During execution, different firmware is read additionally from external memory, and the hardware is changed to correspond to a totally different function. Huge applications that cannot be fully loaded to the chip can be executed by time sharing. The switching time is several hundred μs (in the case of a 40nm core)
STP Engine Sample Applications
The STP engine can perform complex functions in a short amount of time and is therefore ideal for devices handling advanced algorithms or communications protocols for which specifications change frequently.
Use Cases (Typical Examples)
- Commercial imaging equipment (Sony Corporation)
- Digital broadcasting transmitters (Yoozma Corporation)
- Digital cameras
Applications
- Digital audiovisual equipment (image, video, audio)
- Supports a variety of encoders
- Switch between encode and decode
- Broadband communication devices
- Supports a variety of protocols
- Supports future communication standards
- Office equipment
- Variable power, filtering, error diffusion processing
- Supports multiple scanner input formats
- Industrial equipment
- Motor control
- Measurement devices