
‘It is not only about what you say. It is also about how you say it.’ This old-age adage quite aptly sums up the need for human beings to communicate effectively with each other. The necessity of humans to interconnect with one another through voice and sounds has presented a future where communication with machines has become inevitable.
A key enabler for the increasing adoption of voice communication has been accelerated with the expansion of the Internet of Things and artificial intelligence. Integration of AI at the endpoint combined with advances in voice analytics is changing the availability of products and the consumption of product experiences and giving rise to a new ecosystem of companies that are participants and enablers of these products. Intelligent endpoint solutions are making it possible to implement both online and offline systems, reducing reliance on always-on internet/cloud connections. This in turn is creating new opportunities to solve many challenges related to real-time voice analytics across several consumer and industrial applications. The advances in psycholinguistic data analytics and affective computing make allowance for inferring emotions, attitudes, and intent with data-driven modeling of voice. With the voice medium becoming a natural way for humans to interact, it will lead to improvements in measuring intent from voice recognition and voice analytics.
Challenges of Using VUIs
Voice user interfaces (VUIs) allow the user to interact with Endpoint systems through voice or speech commands. Despite mass deployments across a wide range of applications, VUIs have some limitations.
- Poor sound quality- Inconsistent sound quality with continued background noise can make voice recognition a challenge. Voice controllers in IoT can only operate flawlessly if the sound is crystal clear which is a formidable task in a noisy environment. A voice-enabled assistant can only be truly effective if it is able to support different languages and accents, as well as isolate the human voice from the background noise.
- Power consumption- Voice Command systems are restrictive as they require the activation of at least one microphone as well as the processor that recognizes the wake word.
- Real-time processing:
Slow or congested networks can result in command latencies that can impact the user experience. This issue may be addressed by implementing distributed intelligence at the endpoint with the ability to process the voice command in real time without any reliance on the centralized cloud system.
- Accuracy and noise immunity
Voice recognition accuracy and background noise immunity are always major concerns when designing any VUI system. Voice recognition presents a number of challenges as there can be multiple sound sources including interior and exterior noise and echoes from surfaces in the room etc. Isolating the source of a command, canceling echoes and reducing background noise requires some sophisticated technology depending on multiple microphones, beamforming and echo cancellation, along with noise suppression.
Renesas Electronics is addressing these challenges by using state-of-the-art microcontrollers and partner-enabled intelligent voice processing algorithms which makes it easier for product manufacturers to integrate highly efficient voice commands. Renesas Electronics is providing general purpose MCUs enabling cost-optimized VUI integration without compromising on performance and power consumption.
Requirements for Robust Voice Recognition
To make the experience compelling for the user, devices need to be equipped with several components to ensure robust voice recognition.
Command Recognition
One of the most significant features of a voice-enabled device is its ability to identify speech commands from an audio input. The speech command recognition system on the device is activated by the wake word which then takes the input, interprets it, and transcribes it to text. This text ultimately serves the purpose of the input or command to perform the specific task.
Voice Activity Detection
Voice activity detection (VAD) is the process that distinguishes human speech from the audio signal and background noise. VAD is further utilized to improve the optimization of overall system power consumption otherwise the system needs to be active all the time resulting in unnecessary power consumption. The VAD algorithm can be subdivided into four stages:
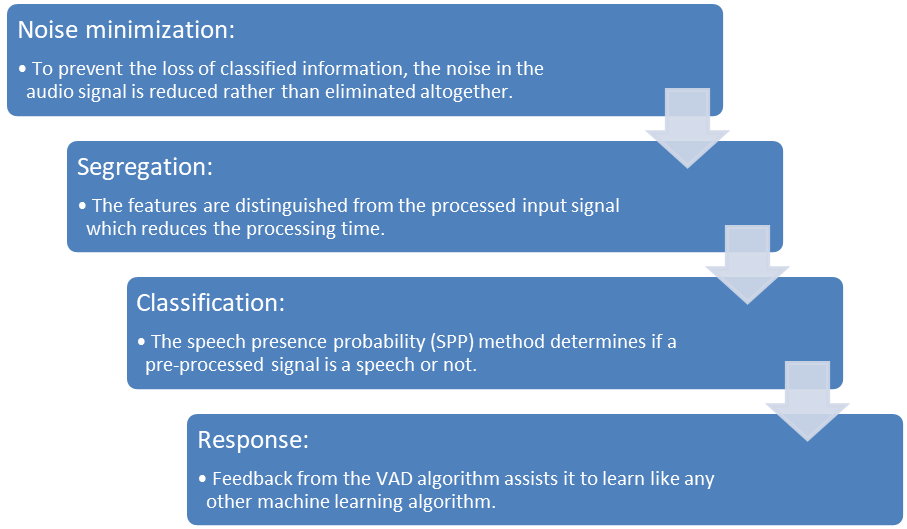
The Renesas RA voice command solution built on the RA MCU family and partner-enabled voice recognition MW boasts a robust noise reduction technique that helps in ensuring high accuracy in VAD. In addition, Renesas can help to address some of the key voice command features outlined below:
Keyword Spotting
Keyword spotting systems (KWS) are one of the key features of any voice-enabled device. The KWS relies on speech recognition to identify the keywords and phrases. These words trigger and initiate the recognition process at the endpoint, allowing the audio to correspond to the rest of the query.
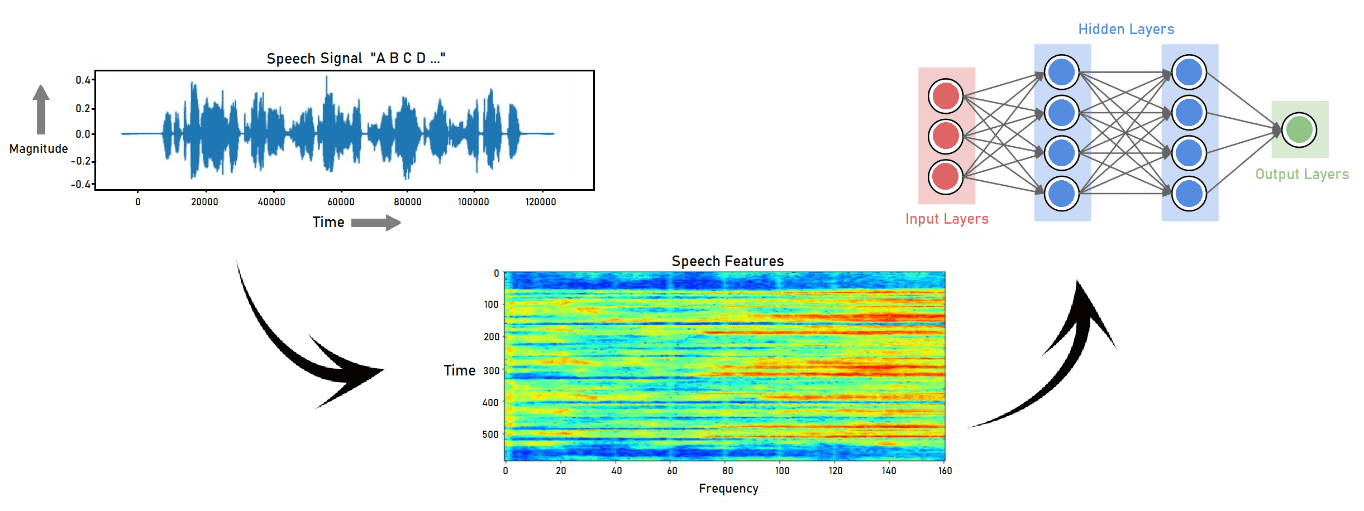
To contribute to a better hands-free user experience, the KWS is required to provide highly accurate real-time responses. This places an immense constraint on the KWS power budget. Therefore, Renesas provides partner-enabled high-performance optimized ML models capable of running on our advanced 32-bit RA microcontrollers. They come with pre-trained DNN models which help in achieving high accuracy when performing keyword spotting.
Speaker Identification
Speaker identification, as the name suggests, is the process of identifying which registered speaker has the given voice input. Speaker recognition can be classified as text dependent, text independent, and text prompted. To train the DNN for speaker identification, individual idiosyncrasies such as dialect, pronunciation, prosody (rhythmic patterns of speech), and phone usage are obtained.
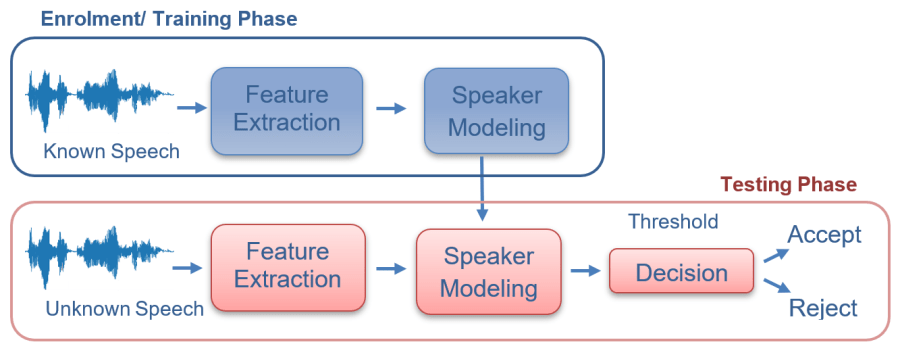
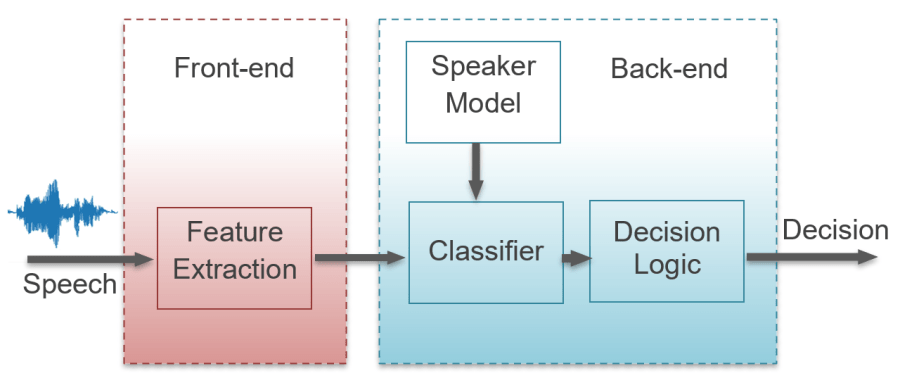
Voice/Sound Anti-Spoofing
Spoofing is a type of scam where the intruder attempts to gain unauthorized access to a system by pretending to be the target speaker. This can be countered by including anti-spoofing software to ensure the security of the system. The spoofing attacks are usually against Automatic Speaker Verification (ASV) systems. The spoofed speech samples can be generated using speech synthesis, voice conversion, or by just replaying recorded speech. These attacks can be classified as direct or indirect depending on how they interact with the ASV system.
- Direct Attack – This can occur through the sensor at the microphone and transmission level and is also known as Physical Access.
- Indirect Attack – This is an intrusion into the feature extraction, models, and the decision-making process of the ASV system software and is also known as Logical Access attack.
Multi-Language/Accent Recognition and Understanding
Accent recognition in English-speaking countries is a much smoother process due to the availability of training data, hence accurate predictions. The downside for organizations operating in countries where English is not the first language is less precision with speech recognition due to the availability of a limited amount of data. An inadequate amount of training data makes building conversational models of high accuracy challenging.
One of the Renesas VUI partner-enabled solutions supports more than 44 languages making it a highly adaptable speech recognition solution that can be used by any organization worldwide.

Renesas invites you to take advantage of this opportunity as it implements a comprehensive solution platform that simplifies voice integration adoption based on our advanced microcontrollers. Our RA MCU-based and partner-enabled voice command solutions offer not only low BOM costs, integrated security, and low latency, but also provide the capability to run at an endpoint. We provide value-added features like local voice triggers, command recognition, robust noise reduction, voice activity detection, and multi-language support just to name a few. This is complemented by a fully featured voice solution development suite and endpoint capable MW for its partners that provide a DNN-based pre-trained voice model where the user can quickly create voice commands with a simple text input. In short, it can be used as it is or tailored to meet individual needs!