
エッジAIはもはや未来の技術ではなく、産業オートメーションからコンシューマー向けIoTアプリケーションに至るまで、今日のスマートデバイスを支える重要な技術となりました。しかし、エッジでAIアプリケーションを構築するには、AIモデル開発の複雑さ、ハードウェア仕様上の制約、さらには長い開発期間といった課題が依然として存在します。
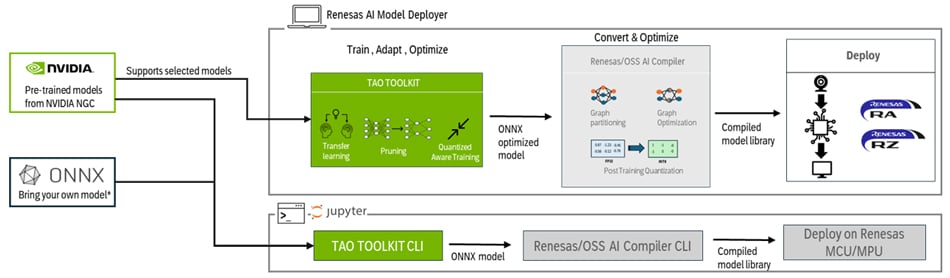
Renesasは、MPU(RZ/V2シリーズ)及びMCU(RA8シリーズ)に対応した、ノーコード感覚で扱えるグラフィカルユーザーインターフェース(GUI)に、NVIDIAの強力なTAO Toolkitを統合することで組み込み開発者が直面する従来の障壁を取り除き、開発の簡素化を実現します。Vision AI開発を始めたばかりの方も、エッジへの展開を最適化する事を目指す方も、このGUIを使って効率的かつスケーラブルな開発を可能にします。
Renesas AI Model Deployerは、標準的なワークステーション環境下で動作するよう設計されており、クラウドベースのインフラを必要とせず、開発者が手軽にプロトタイピングやテスト、評価を行うことができます。
さらに、もっと踏み込んだ開発がしたいエンジニアの為に、詳細なJupyterノートブックも提供されており、カスタマイズ、統合、最適化の高度なレベルまで掘り下げることが可能です。これにより、すぐに開発を始めたい方にも、自分だけのソリューションを自由に構築したい方にも、柔軟に対応できます。
NVIDIA TAOとは?そして、なぜ重要なのか
TAO(Train, Adapt, Optimizeの略)は、NVIDIAが提供するローコードのAI開発環境で、Vision AI向けディープラーニングモデルの構築を劇的にシンプルにしてくれます。TensorFlowやPyTorchの上に構築されており、最新のニューラルネットワークのトレーニングに伴う複雑さを大幅に抽象化すことが可能です。
もちろんゼロからモデルを作る必要はありません。物体検出、分類、セグメンテーションなど、100種類以上の事前学習済みモデルから選んで活用できます。さらに、以下のような重要なAI開発機能もサポート:
- 転移学習: 大規模モデルを自分のデータセットでファインチューニング。必要なデータ量と開発時間を大幅に削減します。
- プルーニング: 不要なウェイトを削除してモデルを軽量化、または精度向上を実現。エッジデバイスでの高速推論にも最適です。
- 量子化対応トレーニング(QAT): INT8を見越したトレーニングで、エッジ向けに最適化されたモデルを実現します。
- ONNX形式へのエクスポート: 学習済みモデルを他のフレームワークやデバイスへ簡単に移行も可能。
そして何より、TAOはローコード環境でこれらの機能を提供しており、AIフレームワークや機械学習理論の深い知識がなくても扱えるのが魅力です。
しかし忘れてはならないのは、例えローコードとはいえ現場の組み込み開発者にとっては、フレームワークのセットアップ、モデル形式とハードウェアの互換性、AIの専門知識なしでのチューニングなど、現実的なハードルが残っているのも事実です。
Renesas AI Model Deployer
ここで真価を発揮するのが Renesas AI Model Deployerです。以下の機能追加により現場の課題をスマートに解決します:
- プロジェクト作成から学習・評価・組み込みまでをガイドするワークフロー
- 統合されたツールチェーンで、面倒なセットアップやライブラリの不整合を回避
- ハードウェアを意識した最適化機能で、エッジ展開に即対応
つまりこのGUIは、以下のようなメリットを皆さんに提供します:
- AIの専門知識がなくても、組み込みエンジニアがすぐに使い始められる
- ベストプラクティスを組み込んだシンプルなフローで、PoCまでの時間を大幅短縮
- 各ステップでハードウェア互換性を保証し、デプロイの信頼性を向上
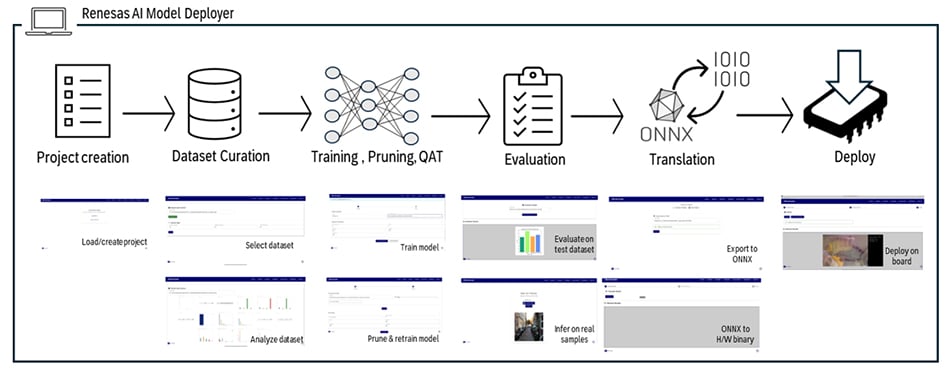
Renesas AI Model Deployer は、Vision AIワークフローをゼロから実装までワンストップ効率的に管理したい組み込み開発者のために設計された、ツールです。たった2つのシェルスクリプト(shell script)を実行するだけで環境を構築でき、以下AI開発パイプラインをGUI上で一貫して実行できます:
- プロジェクト作成(モデル・ボード・タスクの選択)
- データセットの分割と分析
- モデルの学習と最適化(QATやプルーニング対応)
- mAPやTop-K精度による視覚的な評価
- サンプルベースの推論テスト
- ハードウェアへのスムーズなデプロイ
さらに、ライブカメラ推論やUSBストリーミング、直感的なデプロイ画面にも対応しており、開発者はリアルな環境で即座にフィードバックを得ることができます。最先端のAI技術をクリック操作で扱えるこのGUIで、開発者はよりスマートで効率的なエッジ製品を、より早く、より簡単に、そして低リスクで実現できます。
応用やカスタマイズに挑戦したい方は、提供されているJupyterノートブックを使えば、さらに柔軟な開発が可能になります。開発者は、独自のデータ前処理ワークフローを組み込んだり、TAO Toolkitの高度な機能――たとえば、洗練されたデータ拡張戦略やハイパーパラメータのチューニング、さらにはBYOM(BYOM: Bring Your Own Model)の導入まで、自由に拡張できます。これらのノートブックは、GUIで構築した基盤をリアルなアプリケーションに対応できる、完全にカスタマイズ可能なツールキットへと進化させてくれます。
実例をご紹介
Renesas AI Model Deployer は、さまざまなデバイスやAIユースケースに対応した柔軟かつスケーラブルなツールチェーンであることを示す、実践的な統合サンプルを複数サポートしています。これらの例は、MPUからMCUまでのモデル統合・最適化・組み込みを効率化し、現場で使えるAI実装をより身近に、そして本番運用レベルで実現できることを示しています。
実装例一覧:
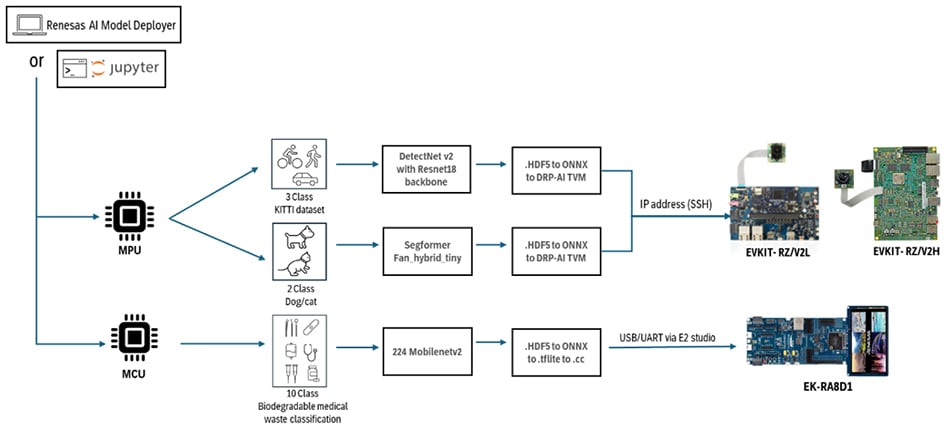
RZ/V2H・RZ/V2L MPUによる物体検出(DetectNet v2使用)
- モデル: DetectNet v2(ResNet-18バックボーン)
- データセット: KITTI(車両・歩行者・自転車)
- 推論性能:RZ/V2Hで約30ms、RZ/V2Lで約200ms
- デプロイ: DRP-AIによる量子化モデルを使い、ライブカメラ推論+バウンディングボックス表示に対応
RZ/V2シリーズ MPUによる画像分類(SegFormer-FAN使用)
- モデル: SegFormer-FAN(Vision Transformerハイブリッド)
- データセット: 猫・犬分類(MPU上でのViT性能を検証するPoC)
- デプロイ: PyTorchで学習 → ONNXエクスポート → DRP-AIで量子化、というエンドツーエンドのワークフロー
RA8D1 MCUによる画像分類(MobileNetV2使用)
- モデル: MobileNetV2
- データセット: 医療廃棄物の分類(注射器、手袋、ピペットなど10クラス)
- 推論性能:Cortex-M85ベースのRA8D1で約120ms
- デプロイ: TFLiteによる量子化 → e² studio経由でMCUに展開
これらの例を通じて、Renesas TAO GUIがどれだけ実用的かつ現場志向のツールであるかを体感できます。GUIベースでありながら、本番レベルのAI統合をスムーズに実現できるのが最大の魅力です。
さらに一歩先へ:Jupyterノートブックでの応用開発: これらのすぐに使えるサンプルに加えて、Jupyterノートブックを使えば、より高度な実験やカスタマイズも可能です。
- ご自身のデータセットを統合
- 高度なモデル再学習(リトレーニング)
- BYOM(Bring Your Own Model)による完全カスタムフローの構築
GUIで構築した基盤をベースに、自分だけのAIワークフローを柔軟に拡張もできるのが大きな魅力です。
早速始めましょう
NVIDIA TAOをローカル環境のGUIベースで統合することで、組み込み開発者がVision AIを導入する際のハードルを大きく下げることができます。あらかじめ用意されたワークフロー、強力なエッジプロセッサとの互換性、そしてJupyter Notebookによる柔軟なスケーラビリティにより、プロトタイプから本番展開までのスピードが格段に向上します。
スマート産業用カメラ、AI搭載センサー、次世代IoTデバイスなど、どのような用途であっても、Renesasが提供する統合ツール群が開発を力強くサポートします。
Renesas製ボードでNVIDIA TAO搭載のAI Model Deployerを始めるには、Renesas AI Model Deployer for Vision AIの特設ページをご覧ください。最新のコードやサンプルは、ランディングページからGitHubページにアクセスしてご確認いただけます。


