概要
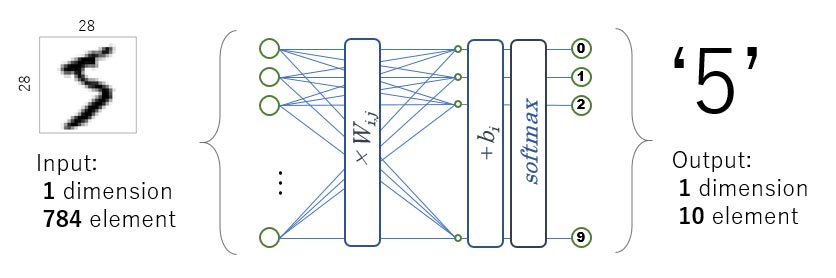
本チュートリアルではTensorflowの例題にある「MNIST For ML Beginners」で、e-AIトランスレータ用のファイルを出力し、GRボードで実行するまでの手順を紹介します。
MNISTの例題は全結合層一層のコンパクトなAIです。
準備
ハードウェア
いずれかのGRボードを準備してください。ただし、GR-KURUMI、GR-COTTON、GR-ADZUKIは本チュートリアルで出力されるCソースに対してROM容量が足りないため、ボードでの実行はできません。
Python, TensorFlow
Tensorflowのインストールページに記載されている手順に沿って、PythonとTensorflowが実行できる環境を構築してください。pipコマンドで最新にアップグレードすることを推奨します。
pip3 install --upgrade tensorflow
e-AIトランスレータ
このチュートリアルではWebコンパイラのe-AIトランスレータを使用しますので、インストール不要です。 なお、e2 studioのプラグインでe-AIトランスレータを使用することもできますので、その場合はe-AIトランスレータのマニュアルを参照してインストールを行ってください。
コンパイル(ビルド)環境
このチュートリアルではWebコンパイラでビルドしてGRボードで実行できるバイナリ(binファイル)を生成しますので、インストール不要です。
なお、e2 studioでのビルド環境でもできますので、その場合はe2 studioでビルドを行ってください。
機械学習の実行
e-AIトランスレータ用の学習済みAIモデルを出力するため、以下のMNIST用Pythonコードを実行します。オリジナルのコードとの違いについては巻末の解説を参照してください。
以下のリンクをクリックするとダウンロードが始まります。任意のフォルダにダウンロードし解凍してください。
Python Code for MNIST (ZIP)
ターミナルでダウンロードしたフォルダに移動し、以下のコードを実行してください。python mnist_softmax_for_e-ai.py
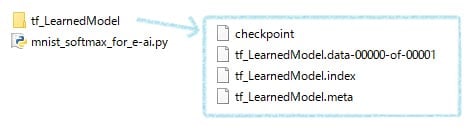
以下のようにtf_LearnedModelに4つのファイルが生成されます。これがe-AIトランスレータ用の学習済みAIモデルとなります。
e-AIトランスレータの実行
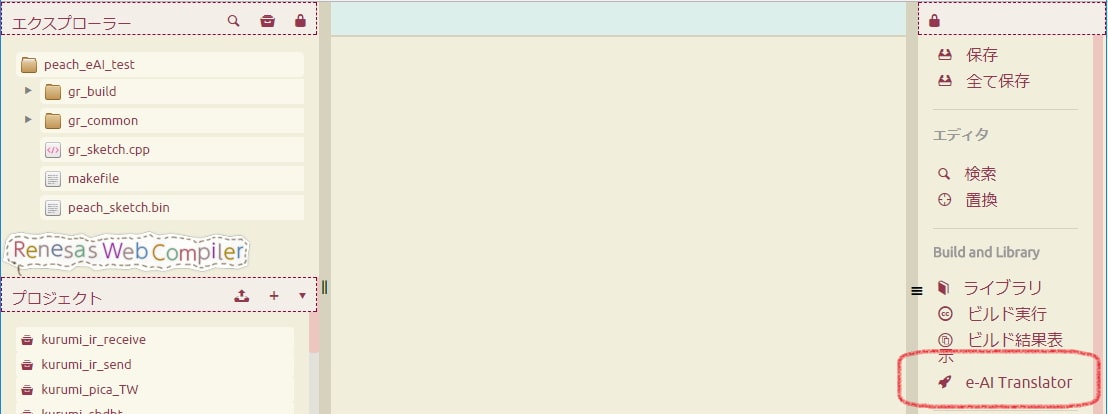
Webコンパイラにログインして、新規にプロジェクト作成してください。その後以下の「e-AI Translator」ボタンを押してください。
次に「アップロード」ボタンを押して、学習済みAIモデルが格納されたtf_LearnedModelフォルダを指定してください。4ファイルがe-AI_Modelフォルダにアップロードされます。それ以外の設定はそのままで「トランスレート」ボタンを押してください。

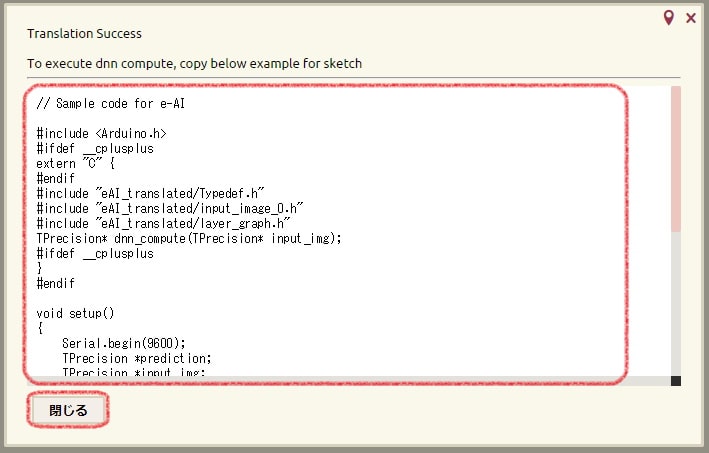
成功すると以下のようにTranslation Successと表示され、サンプルプログラムが表示されます。サンプルプログラムをそのまま使いますので、テキストコピーしておきましょう。コピーしてからウィンドウを閉じてください。
なお、e2 studioのe-AIトランスレータプラグインでも同様にAIモデルを指定してトランスレートができます。
AIの実行
表示されたサンプルプログラムをgr_sketch.cppにコピーしてビルドしましょう。ビルド後のbinファイルをGRボードで実行し、シリアルモニターを表示すると、以下のように推論にかかった時間と、推論結果が表示されます。なお、筆者はGR-PEACHで実行しましたが、この場合約0.4ms程度で実行されるようで、時間は0と表示されています。
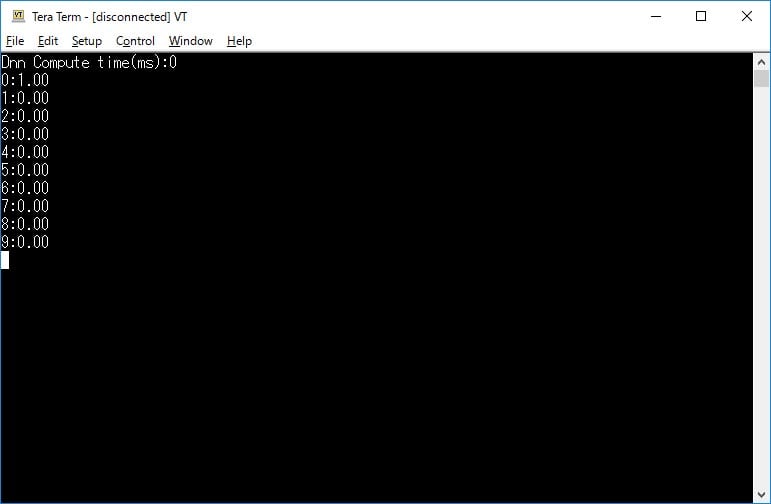
以下、画像をクリックするとサンプルヘッダをダウンロードできます。今回はあらかじめ用意された手書き数字データを読み込みましたが、例えばカメラ画像から、28x28のfloat型グレーイメージに変換して入力すれば、数字の判別を行うことができます。
![]()
![]()
![]()
![]()
![]()
![]()
解説:e-AIトランスレータの入力ファイルについて
今回の入力ファイルは下記URLのPythonコードに対して、e-AIトランスレータ用にコードを追加しています。
追加しているのは下記ソースで強調表示されている81~89行です。学習後のAIをグラフ構造で出力するコードを学習終了後の位置に追加しています。他のAIモデルを出力するときにこれを参考にしてください。
なお、41~46行目のコメントアウト部分はe-AIトランスレータでの設定項目「入力シェイプサイズ」の適用を省くためです。TensorFlowは入力で使った変数をそのまま次の層で使うと、入力変数のshapeを得ることができません。一度別の変数で受けると、shapeが固定されるため「入力シェイプサイズ」の設定に依存しないようになります。
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A very simple MNIST classifier.
See extensive documentation at
https://www.tensorflow.org/get_started/mnist/beginners
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = None
def main(_):
# Import data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
#Add Renesas 2 --------- ----------
# change
# x_ = tf.placeholder(tf.float32, [None, 784])
# x = tf.reshape(x_, [-1])
# --------- ----------
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + b
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.nn.softmax(y)),
# reduction_indices=[1]))
#
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the raw
# outputs of 'y', and then average across the batch.
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Train
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
#Add Renesas 1 --------- ----------
import os
#Save Learned AI
out_dir = "./tf_LearnedModel"
if os.path.isdir(out_dir) is False:
os.makedirs(out_dir)
saver = tf.train.Saver()
saver.save(sess, out_dir+"https://www.renesas.com/tf_LearnedModel")
# --------- ----------
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='https://www.renesas.com/tmp/tensorflow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
解説:e-AIトランスレータの出力ファイルについて
e-AIトランスレータによって出力されるファイルの概要を示します。ファイルの中身はWebコンパイラでファイルをダブルクリックして確認してみてください。
| ファイル名 | 概要 |
|---|---|
| dnn_compute.c | 変換したニューラルネットワークの推論実行関数 |
| network.c | ニューラルネットワーク関数ライブラリ |
| layer_graph.h | 変換したニューラルネットワークで使われているライブラリ関数のプロトタイプ宣言 |
| layer_shapes.h | 変換したニューラルネットワークで使う変数定義 |
| weights.h | 変換したニューラルネットワークの重み,バイアス値 |
| Typedef.h | ライブラリを使う際の型定義 |
| input_image_0.h | MNIST形式のサンプル文字データ |
| network_description.txt | ニューラルネットワークの構造を解析した結果認識した層定義と,その構成 |
| checker_log_output.txt | 上記解析した構造から,数式を使い目安となるROM/RAM容量計算量を見積もった結果。ただし、スピード優先、RAM消費量低減優先のオプションは未考慮。実際には,ノードの値を引数で再定義するため,実際の必要容量は2~3倍となる |
