
Background
Model transformation of deep learning for real-time processing for automotive SoCs
Deep learning is developed using underlying software (deep learning frameworks) such as TensorFlow and PyTorch.
By simply porting the models learned in a deep learning framework as is, it is impossible to perform real-time processing on an in-vehicle SoC such as R-Car, because the inference process of deep learning requires a great deal of computation and memory usage. Therefore, it is necessary to apply non-equivalent model compression such as quantization and pruning to the trained model, and performance optimization using a deep learning compiler.
First, let us discuss model compression. In quantization, the inference process, which is usually computed in floating point, is converted to approximate integer operations such as 8-bit. Pruning reduces computation and memory usage by setting weights that contribute little to the recognition result to zero and skipping the computation for those weights. Both of these transformations are non-equivalent algorithmic transformations to the original inference process and are likely to degrade recognition accuracy.
To optimize performance, the deep learning compiler transforms the program for the inference process of the trained model so that it can be processed faster by a deep learning accelerator, or it applies memory optimization such that fast and small SRAM allocated to output data in one layer can be re-used for output data in another layer.
Applying such a conversion process enables real-time processing on an automotive SoC.
Inference flow in R-Car using Renesas tools and software
CNN-IP, the H/W accelerator in Renesas' R-Car, can perform inference operations using integer values for reasons of computational efficiency. For this reason, the user must use the R-Car CNN tool provided by Renesas to perform quantization, one of the model transformations described above.
First, before actually performing the quantization, calibration must be performed to calculate the quantization parameters (Scale and Zero point) to convert the floating numbers to integers. For this purpose, an external tool (TFMOT, ONNX runtime, etc.), depending on the format of the network model, is used to obtain the maximum and minimum output values for each layer from a large number of input images. From these maximum/minimum values, quantization parameters such as scale/zero point can be calculated, and the R-Car CNN tool uses these quantization parameters to quantize the parameters for each layer.
The R-Car CNN tool then creates a Command List from the network model and the quantized parameters of each layer. The Command List is a binary data file that tells CNN-IP which commands to execute and which parameters to set. By giving this Command List to the CNN-IP, inference can be performed.
Since the Command List is uniquely determined from the network model and quantization parameters, it only needs to be created once in advance. By executing the aforementioned Command List for each image, inference can be performed on the actual device.
Figure 1 shows a block diagram of inference on R-Car V4H using Renesas tools and software.
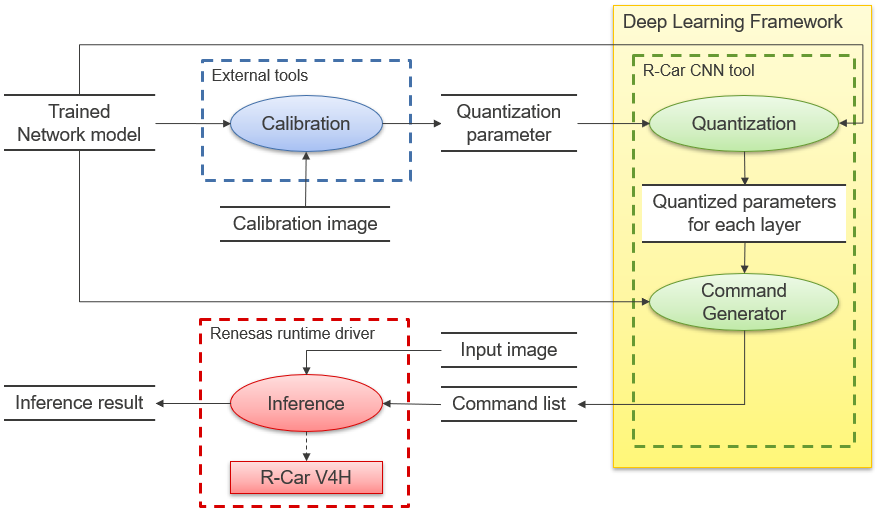
Figure 1. Block diagram of reasoning with Renesas tools and software
About each simulator
Overview and features of each simulator
Renesas has prepared simulators to solve the following two user challenges:
A) Before developing an application, the user wants to check the change in accuracy due to quantization.
B) To check and debug user applications using Command List without using actual devices.
There are three types of Renesas simulators, each of which addresses different tasks and has different features. The features of each are shown in Table 1. Each has different accuracy and processing speed. For each, we will introduce the details of the features and use cases, referring to the block diagram.
Table 1. Overview and Features of Each Simulator
| Challenge | Name | Speed | Accuracy | Input | Output |
|---|---|---|---|---|---|
| B | Instruction Set Simulator (ISS) | Slow | Device exact match | Input image Command List (*1) | Inference result |
| A | Accurate Simulator | Medium | Device exact match | Input image Network model Quantized parameters of each layer (*2) | Inference result |
| Fast Simulator | Fast | Errors found | Input image Network model Quantized parameters | Inference result |
(*1) The Command List is created using the R-Car CNN tool based on the network model and quantization parameters, following the same procedure for inference on the actual device as described above.
(*2) Accurate Simulator runs within the R-Car CNN tool. When the user provides the R-Car CNN tool with the network model and quantization parameters, the tool automatically calculates the quantized parameters for each layer, which are then input to Accurate Simulator.
ISS
This simulator is designed to debug output results using the same software configuration and input data (Command List, mainly register settings) as the actual device as much as possible. It does not reproduce timing and is not intended for timing verification.
The results are exactly the same as on the actual device, and the speed is slower than the Accurate Simulator because the output is reproduced on an instruction basis.
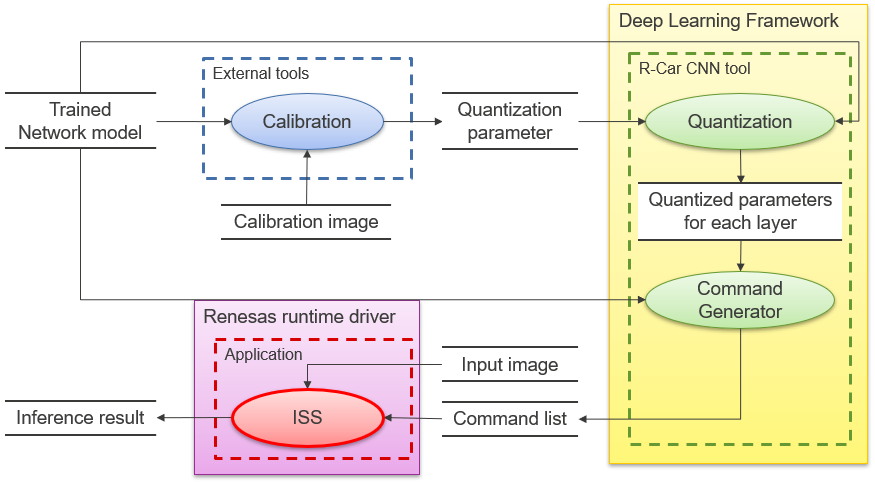
Figure 2. Block diagram of a system using ISS
Accurate Simulator
This simulator takes a network model as input and is used to verify accuracy without using actual devices. For each layer, an algorithm is implemented such that the output is a perfect match to the device's calculation algorithm. Since it is about 10 times faster than ISS, it is useful only for verifying accuracy.
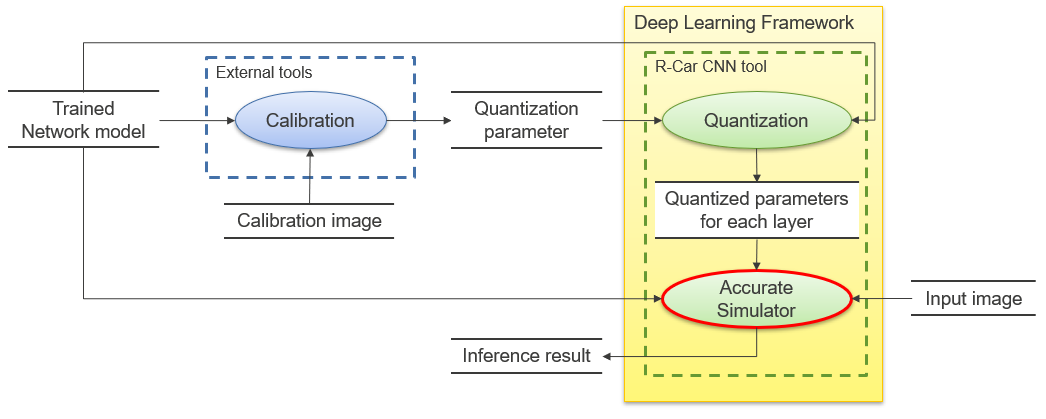
Figure 3. Block diagram of a system using Accurate Simulator
Fast Simulator
This simulator is used to check the quantization error for a large number of images.
Fast Simulator extends pseudo-quantization functionality to the deep learning framework (Tensor Flow in R-Car V4H) after each layer of inference operations with floating-point numbers. Pseudo-quantization is a method of reproducing pseudo-quantization errors by adding the same amount of error to floating-point numbers as the degradation in accuracy due to quantization without changing the floating-point numbers.
By adding only the pseudo-quantization function to Tensor Flow, which runs at high speed, it is possible to make it run at speed similar to Tensor Flow at high speed.
Also, since the input/output interface is common to the deep learning framework, it is easy for users to check quantization errors while switching between the deep learning framework.
However, since inference operations and pseudo-quantization in each layer generate slight floating-point arithmetic errors, the results are not in perfect agreement with the results of the actual operations.
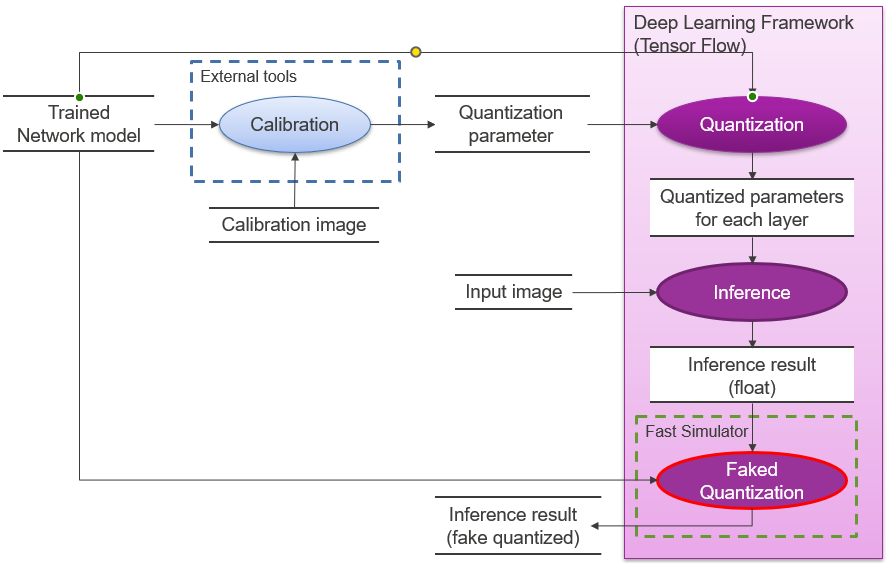
Figure 4. Block diagram of a system using Fast Simulator


