
e-AI Translator とは
オープンソースのAIフレームワークを用いて作成した学習済みAIアルゴリズムを推論専用のCソースコードに変換するツールです。このe-AI Translatorの最新版V2.3.0を2022年10月4日にリリースしました。
本ブログでは、V2.3.0の強化された機能「CMSIS_INT8ライブラリ利用時の速度向上とRAM使用量の削減」についてご紹介いたします。また、更なる高速化の手法として、理解していただきたいe-AI Translatorが取り扱うライブラリのデータセットの構造についても紹介いたします。本内容はRAファミリ、RXファミリで使用可能です。
1.CMSIS_INT8ライブラリ利用時の速度向上とRAM使用量の削減
CMSIS_INT8ライブラリは、e-AIトランスレータV2.2.0で実装した機能です。Renesas RX/RAファミリーのマイコン製品の内蔵DSP/FPUを利用するため、OSSフリーであるC_FP32/C_INT8ライブラリを利用した場合よりも高速に演算できることが特徴です。一方、V2.2.0ではCMSIS_INT8ライブラリを選択した場合に、CMSIS_INT8ライブラリが内部で使用するワークメモリを別途確保する必要があったため、C_FP32/C_INT8ライブラリ使用時よりも、必要メモリ量が最大で2倍程度増加していました。
これに対して、e-AIトランスレータV2.3.0は量子化のパラメータを一部ROMに置くことで、必要とするRAMサイズを大幅に低減しました。特にConvolutionを多く利用するネットワーク構造では、C_INT8ライブラリ使用時よりも必要なRAMサイズを縮小することが可能となりました。
その効果を、MCU向けAIの標準ベンチマークである、MLCommonsの MLPerf™ Tiny Inference benchmarkのモデルを使って確認していきます。
表1: e-AI Translator V2.2.0とV2.3.0との推論速度、メモリサイズ比較
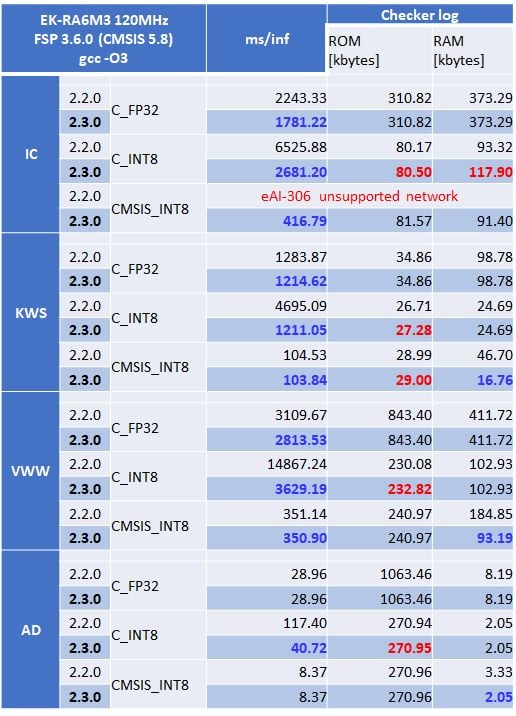
※青字:V2.2.0より改善された項目 赤字:必要メモリ量が増加した項目
MLPerf™ Tinyのモデルは、ResNet構造を持つICモデルのみが分岐構造を持ちます。e-AI Translator V2.3.0は、CMSIS_INT8ライブラリを使用した場合の分岐構造に対応しました。
表1を使って、C_INT8ライブラリ使用時と、C_FP32ライブラリ使用時の比較をしてみましょう。C_INT8ライブラリは、C_FP32ライブラリを使った時よりも、ROMのサイズが1/4に、RAMのサイズが1/2~1/3となります。
一方、一つのInt8関数の計算が終了するたびに、次の関数入力値をInt8の範囲内に収めるための、再量子化計算が行われるため、C_FP32ライブラリ使用時よりも全体の推論時間が50%ほど遅くなってしまいます。ただ、C_INT8ライブラリ使用時の推論速度は、V2.3.0でConvolution直後のReLUなど、処理が重複していた無駄な計算を削除した効果により、V2.2.0より1.5倍以上高速になりました。その結果、DSPやFPUを持たないなどの理由により、CMSIS_INT8ライブラリが使用できないマイコンで、より複雑なAIモデルを実用的な速度で利用することが可能となりました。
次に、CMSIS_INT8ライブラリ使用時と、C_INT8ライブラリ使用時の比較をしてみましょう。CMSIS_INT8ライブラリ使用時は、V2.3.0で行ったデータ構造の最適化により、若干ROMサイズが増えるものの、必要なRAMサイズがC_INT8ライブラリ使用時並みに削減されました。
その結果、推論速度はC_FP32ライブラリ使用時よりも大幅に向上し、ROM/RAMサイズはC_INT8ライブラリ使用時並みの、高速かつコンパクトなAIアルゴリズムとして利用することが可能となりました。TensorFlow LiteのINT8モデルを使う場合は、CMSIS_INT8ライブラリを使用することをお勧めいたします。
なお、RAシリーズのマイコンでCMSIS_INT8ライブラリを使用する場合は、FSP3.5以上FSP3.71以下を利用し、FSPのComponentでCMSIS/DSP、CMSIS/NNを追加してください。RXファミリーのマイコンでCMSIS_INT8ライブラリを使用する場合は、別途、CMSIS for RXを入手してください(無料)。CMSIS for RXは、CMSISライブラリの関数の内、良く利用され、かつ、実行時間削減効果の高い関数に対して、RXシリーズのマイコンに内蔵されているDSP命令を利用するように改変したライブラリです。使用方法の詳細はe-AIトランスレータのユーザーズマニュアル、およびCMSIS for RXのアプリケーションノートを参照してください。
2.更なる高速化のTIPS
2-1.データ構造の理解
AIフレームワークは数多く存在しますが、主流となっているデータ構造は以下の2種類です。
- Channel First:Caffe, PyTorchなど
- Channel Last: TensorFlow,Kerasなど
Convolution2D で使われる4D shapeのデータ構造で見ると分かりやすいと思います。
- Channel First: [nCHW]
- Channle Lasr: [nHWC]
n:the Number of datas(images) in batch C:Channel H:Height W:Width
e-AIトランスレータはChannel Firstを想定しています。画像データはChannel last(カラー情報が最後)となることが多いのですが、演算が高速なChannel Firstのデータ構造をライブラリで採用しています。そのためe-AIトランスレータで変換すると、推論関数であるdnn_compute関数は入出力がChannel First形式のデータ構造である必要があります。
一方、V2.2.0から採用したCMSIS_INT8ライブラリは、Channel Lastのデータ構造をとっています。e-AIトランスレータのdnn_compute関数は入出力がChannel Firstであることを想定しますので、4D shapeの入出力でCMSIS_INT8ライブラリを指定すると、以下のようにnCHWからnHWCへ変換する処理が追加されます。
例) Conv2D-Conv2D-Conv2DTrasnspose-Conv2DTraspose (CNN AutoEncorder)
e-AI Translator 実行後のTranslator/dnn_compute.cのソースコード(抜粋)
TsOUT* dnn_compute(TsIN* input_1_int8, TsInt *errorcode)
{
*errorcode = 0;
//Converting the dataformat from NCHW to NHWC;
transpose4d(input_1_int8,dnn_buffer1,layer_shapes.input_1_int8_tr_shape,errorcode);
arm_convolve_s8(※引数省略);
:
:
:
sigmoid(※引数省略);
//Converting the dataformat from NHWC to NCHW;
transpose4d(dnn_buffer1,dnn_buffer2,layer_shapes.Identity_int8_tr_shape,errorcode);
return(dnn_buffer2);
}
2-2.CMSIS_INT8指定時に更に高速化する方法
Transpose部分はデータ構造を変換しているだけですので、Transposeしないようにdnn_compute.cを書き換えた上で、推論関数へのデータをChannel Lastの形式で入力する形で使用すれば高速化することができます。
具体的な手順は次のようになります。
Transpose関数は、
- 第一引数:Transpose対象配列
- 第二引数:Transpose後の配列
- 第三引数:Transpose対象配列のshape
- 第四引数:errorcode(mallocエラーの有無)
となっています。
まず、第一引数に使われている変数名を確認してください。
Transpose関数の次の関数で、Transposeの第二引数に使っている変数名を確認してください。
TsOUT* dnn_compute(TsIN* input_1_int8, TsInt *errorcode)
{
*errorcode = 0;
//Converting the dataformat from NCHW to NHWC;
transpose4d(input_1_int8,dnn_buffer1,layer_shapes.input_1_int8_tr_shape,errorcode);
arm_convolve_s8(&cr_buffer,&layer_shapes.model_conv2d_Relu_shape.conv_params,&model_conv2d_Relu_multiplier,&layer_shapes.model_conv2d_Relu_shape.input_dims,dnn_buffer1,&layer_shapes.model_conv2d_Relu_shape.filter_dims,model_conv2d_Relu_weights,&layer_shapes.model_conv2d_Relu_shape.bias_dims,model_conv2d_Relu_biases,&layer_shapes.model_conv2d_Relu_shape.output_dims,dnn_buffer2);
:
:
:
sigmoid(※引数省略);
//Converting the dataformat from NHWC to NCHW;
transpose4d(dnn_buffer1,dnn_buffer2,layer_shapes.Identity_int8_tr_shape,errorcode);
return(dnn_buffer2);
}
第二引数と同一名称の変数名を見つけたら、第一引数の変数名に置き換え、Transposeをコメントアウトしてください。
TsOUT* dnn_compute(TsIN* input_1_int8, TsInt *errorcode)
{
*errorcode = 0;
//Converting the dataformat from NCHW to NHWC;
//transpose4d(input_1_int8,dnn_buffer1,layer_shapes.input_1_int8_tr_shape,errorcode);
arm_convolve_s8(&cr_buffer,&layer_shapes.model_conv2d_Relu_shape.conv_params,&model_conv2d_Relu_multiplier,&layer_shapes.model_conv2d_Relu_shape.input_dims,input_1_int8,&layer_shapes.model_conv2d_Relu_shape.filter_dims,model_conv2d_Relu_weights,&layer_shapes.model_conv2d_Relu_shape.bias_dims,model_conv2d_Relu_biases,&layer_shapes.model_conv2d_Relu_shape.output_dims,dnn_buffer2);
:
:
:
sigmoid(dnn_buffer1,Identity_int8_multiplier,Identity_int8_offset,dnn_buffer1,layer_shapes.Identity_int8_shape,errorcode);
//Converting the dataformat from NHWC to NCHW;
//transpose4d(dnn_buffer1,dnn_buffer2,layer_shapes.Identity_int8_tr_shape,errorcode);
return(dnn_buffer1);
}
この変更によりCMSIS_INT8を指定した場合は、推論関数の入出力データをChannel Lastの形式で取り扱うことが可能となります。
TensorFlow Liteの入出力データの形式をそのまま利用できる上に高速化が見込める方法となります。ぜひ御活用ださい。
2.3 FSP 4.1 (CMSIS V5.9)の利用方法
CMSIS V5.9(CMSIS NN V3.1)のライブラリは、Convolutionの以下のパラメータを利用するように変更されました。
cmsis_nn_tile cmsis_nn_conv_params::dilation
e-AI Translator V2.3.0では、この値を0として Translator/layer_shapes.h に出力しています。そのため、そのままCNSIS V5.9のライブラリを使用した場合、Convolution計算が一部スキップされ、誤った推論結果を出力してしまいます。e-AI Translator V2.2.0/2.3.0が出力した Translator/layer_shapes.h をCMSIS V5.9に含まれるCMSIS NN V3.1で使う場合は、以下の手順でlayer_shapes.hの値を書き換えてください。
Translator/layer_shapes.h に記述されている shapes構造体の中のconv、dconvで始まる行を見つける。
struct shapes{
TsInt input_1_tr_shape[5];
conv functional_1_activation_Relu_shape;
dconv functional_1_activation_1_Relu_shape;
:
:
fc functional_1_dense_BiasAdd_shape;
TsInt Identity_shape;
};
この構造体を使った変数の値の設定を行っている行を確認します。
変数名一つにつき、一行で値を設定しています。
struct shapes layer_shapes ={
// input_1_tr_shape[5];
{1,1,49,10,1},
// functional_1_activation_Relu_shape;
{1,49,10,1,64,10,4,1,1,25,5,64,1,1,1,64,-83,-128,2,2,1,4,0,0,-128,127},
// functional_1_activation_1_Relu_shape;
{1,25,5,64,1,3,3,64,1,25,5,64,1,1,1,64,128,-128,1,1,1,1,1,0,0,-128,127},
:
:
{1,64,64,1,64,1,1,12,1,1,1,12,1,1,1,12,128,0,14,-128,127},
12
};
conv, dconvのパラメータ設定の内、 cmsis_nn_conv_params::dilation に相当するのは、後ろから3,4番目の値です。現在0を出力しているため、この値を1に変更してください。
本修正により、CMSIS NN V3.1以降のdilationを認識するライブラリで正常に動作するようになります。
struct shapes layer_shapes ={
// input_1_tr_shape[5];
{1,1,49,10,1},
// functional_1_activation_Relu_shape;
{1,49,10,1,64,10,4,1,1,25,5,64,1,1,1,64,-83,-128,2,2,1,4,1,1,-128,127},
// functional_1_activation_1_Relu_shape;
{1,25,5,64,1,3,3,64,1,25,5,64,1,1,1,64,128,-128,1,1,1,1,1,1,1,-128,127},
:
:
{1,64,64,1,64,1,1,12,1,1,1,12,1,1,1,12,128,0,14,-128,127},
12
};
ツールダウンロードリンク
アプリケーション > テクノロジー > e-AIソリューション > 開発環境 / ダウンロード
もしくは検索窓を使って、“e-AI”を検索、“開発環境 / ダウンロード”を選択してください
過去blog
- RXやRAファミリのAI推論を10倍以上高速化 CMSISライブラリに対応したe-AI Translator V2.2.0をリリース
- 8bit量子化技術でROM/RAM使用量削減に貢献 TensorFlow Liteに対応したe-AI Translator V2.1.0をリリース
- MCU で AI を実現するツールe-AI Translator V2.0.0 リリース
