

Recently, with advancements in machine learning (ML) there has been a bifurcation, splitting into two scales: traditional large ML (cloud ML) with models getting larger and larger to achieve the best performance in terms of accuracy and the nascent field of tiny machine learning (TinyML), where models are shrunk down to fit into constrained devices to perform at ultra-low power. As TinyML is a nascent field, this blog will discuss the various parameters to consider when developing systems incorporating TinyML and current industry standards into benchmarking TinyML devices.
The four metrics that will be discussed are accuracy, power consumption, latency, and memory requirements. The system metric requirement will vary greatly depending on the use case being developed.
Accuracy has been used as the main metric to measure the performance of machine learning models for the last decade, with larger models tending to outperform their smaller predecessors. In TinyML systems, accuracy is also a critical metric, but a balance with the other metrics is more necessary, compared to cloud ML.
Power consumption, as TinyML systems are expected to operate for prolonged periods on batteries, it’s critical to consider the power consumption of TinyML models (typically in the order of milliwatts). The power consumption of the TinyML model would depend on the hardware instruction sets available, for instance, ARM® Cortex®-M85 is significantly more energy efficient than the ARM® Cortex®-M7 thanks to the helium instruction set. It would also depend on the underlying software used to run the models i.e., the inference engine, for instance using the CMSIS-NN library improves the performance drastically as compared to reference kernels.
Latency, as TinyML systems operate at the endpoint and do not require cloud connectivity, the inference speeds of such systems are significantly better than cloud-based systems. Furthermore, in some use cases, having ultra-high inference speed is critical (in milliseconds) to be production ready. Similar, to the power consumption metric, it depends on the underlying hardware and software.
Memory, is a big hurdle in TinyML, squeezing down your ML models to fit into size-constrained microcontrollers (less than 1 MB). Thus, reducing memory requirements has been a challenge and during model development, many techniques are utilized such as pruning and quantization. Furthermore, the underlying software plays a large role as better inference engines optimize the models more effectively (better memory management and libraries to execute layers).
As the 4 parameters are correlated (tends to be an inverse correlation between accuracy and memory but a positive correlation between memory, latency, and power consumption), improving one, could affect the others, so when developing a TinyML system, it is important to carefully consider this. A general rule of thumb would be to define the necessary model accuracy required as per the use case and then compare a variety of developed models against the three other metrics as shown below, given a dummy example of a variety of models that have been trained.
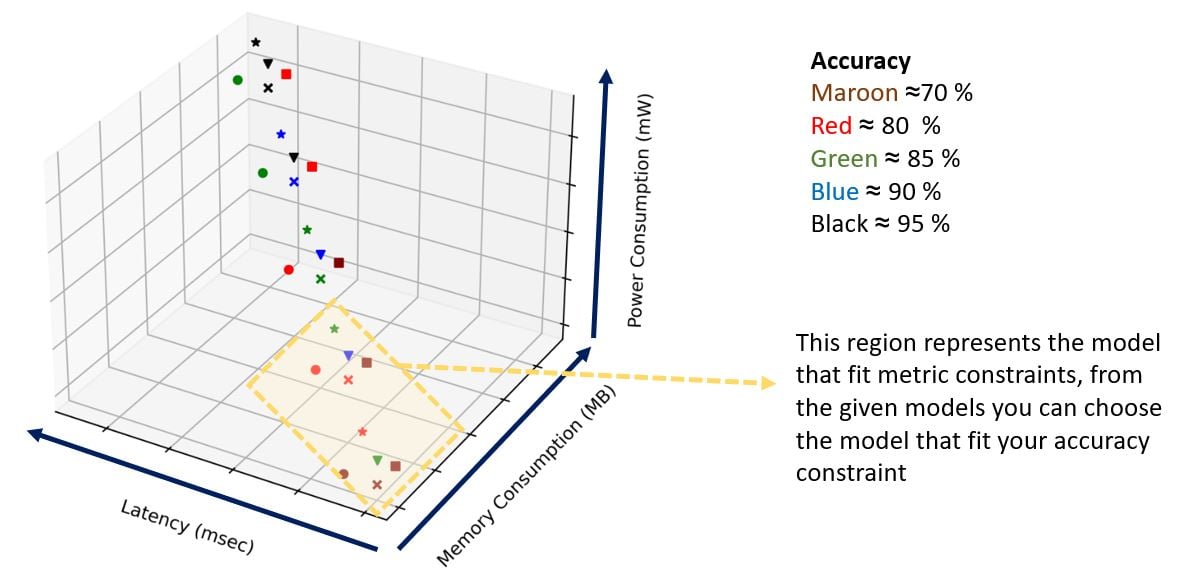
The marker shapes represent different model architectures with different hyperparameters, that tend to improve accuracy with an increase in architecture size at the expense of the other 3 metrics. Depending on the system-defined use case, a typical region of interest is shown, from that, only one model has 90 % accuracy, if higher accuracy is required, the entire system should be reconsidered to accommodate the increase in the other metrics.
Benchmarking TinyML models
Benchmarks are necessary tools to set a reproducible standard to compare different technologies, architectures, software, etc. In AI/ML, accuracy is the key metric to benchmark different models. In embedded systems, common benchmarks include CoreMark and EEMBC’s ULPMark measuring performance and power consumption. In the case of TinyML, MLCommons has been gaining traction as the industry standard where the four metrics discussed previously are measured, and due to the heterogeneity of TinyML systems, to ensure fairness, 4 AI use cases with 4 different AI models are used, and have to achieve a certain level of accuracy to qualify for the benchmark. At Renesas, we benchmarked two of our microcontrollers, RA6M4 and RX65N using TensorFlow lite for microcontrollers as an inference engine and the results can be viewed here.
As industry leaders within the field of endpoint AI and scheduled to be first to market with ARM® Cortex®-M85 core microcontrollers, TinyML systems will be pushed even further to develop use cases to make our lives easier.
If you are interested to know more about the RA family line of MCUs you can click the following link and for the RX family line of MCUs, here.