
アクセラレータ型DRP(STP:Stream Transpose®)はCPUでは処理性能が不足する処理をアクセラレートします。DRPコア直結のDMAコントローラを備え、データ転送を効率的に行えます。処理を定義するファームウェアの書き換えが瞬間に行えますので、ほぼ無限の機能をシステム内に搭載することが可能です。IPコアとして、現在16nm,28nm,40nmプロセスに対応しています。
高性能を追求したアクセラレータ型DRPの構造
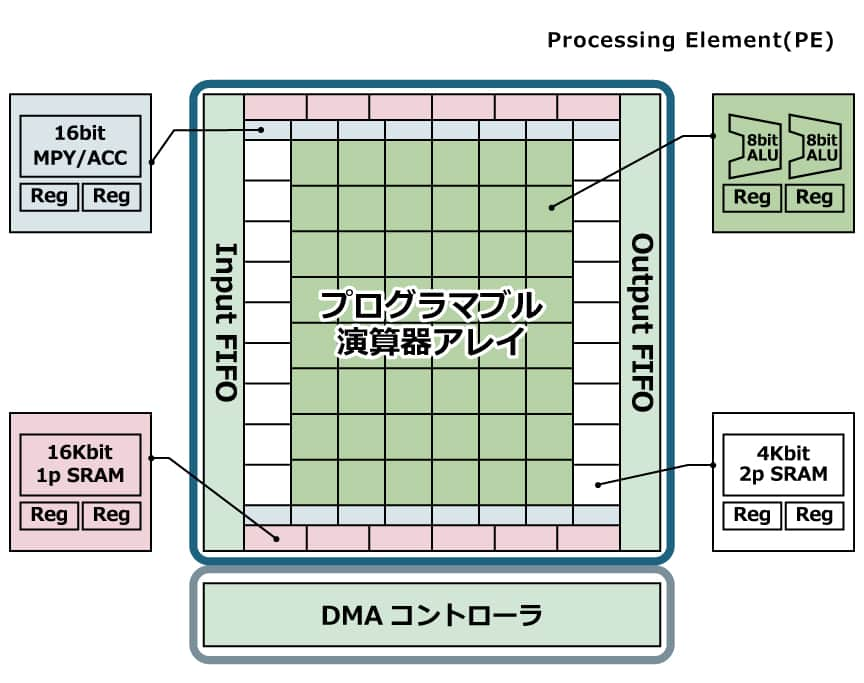
アクセラレータ型DRPはプログラマブル演算器アレイ+DMAコントローラ構造を採用しています。
データ転送(DMA)を処理(プログラマブル演算器アレイ)から分けて専用化しています。これにより性能および面積効率の向上を図りCPU負荷を軽減、システム全体の性能向上を実現します。
プログラマブル演算器アレイは、演算器やメモリで構成されており、8もしくは16ビット演算器(ALU)アレイの周囲をメモリや乗算器が取り囲む構成になっています。アクセラレータ型DRPでは、多くの演算器とメモリを用いて処理を並列に実行することで、より高い性能を実現します。
効率的なデータ転送
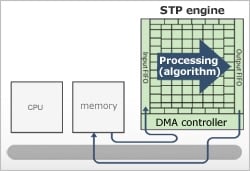
機能を強化したDMAにより、メモリ間のデータ転送を効率的に実行します。DMAとプログラマブル演算器アレイを同時に動かすことで、データの転送オーバーヘッドを削減しています。
アクセラレータ型DRPの検証モデルは設計ツールに組み込まれています。DMAに対するアクセス命令発行と、プログラマブル演算器アレイで実行するアルゴリズムは、同一のCプログラムとして記述することができ、最適化しやすい仕組みになっています。
また、アクセラレータ型DRPとCPUとの機能分担はソフトウェアで変更が可能なため、要求仕様に合わせたフレキシブルなシステムを構築できます。
DRPのハードウェア切替え能力
アクセラレータ型DRPは2種類のハードウェア切り替えを行います。
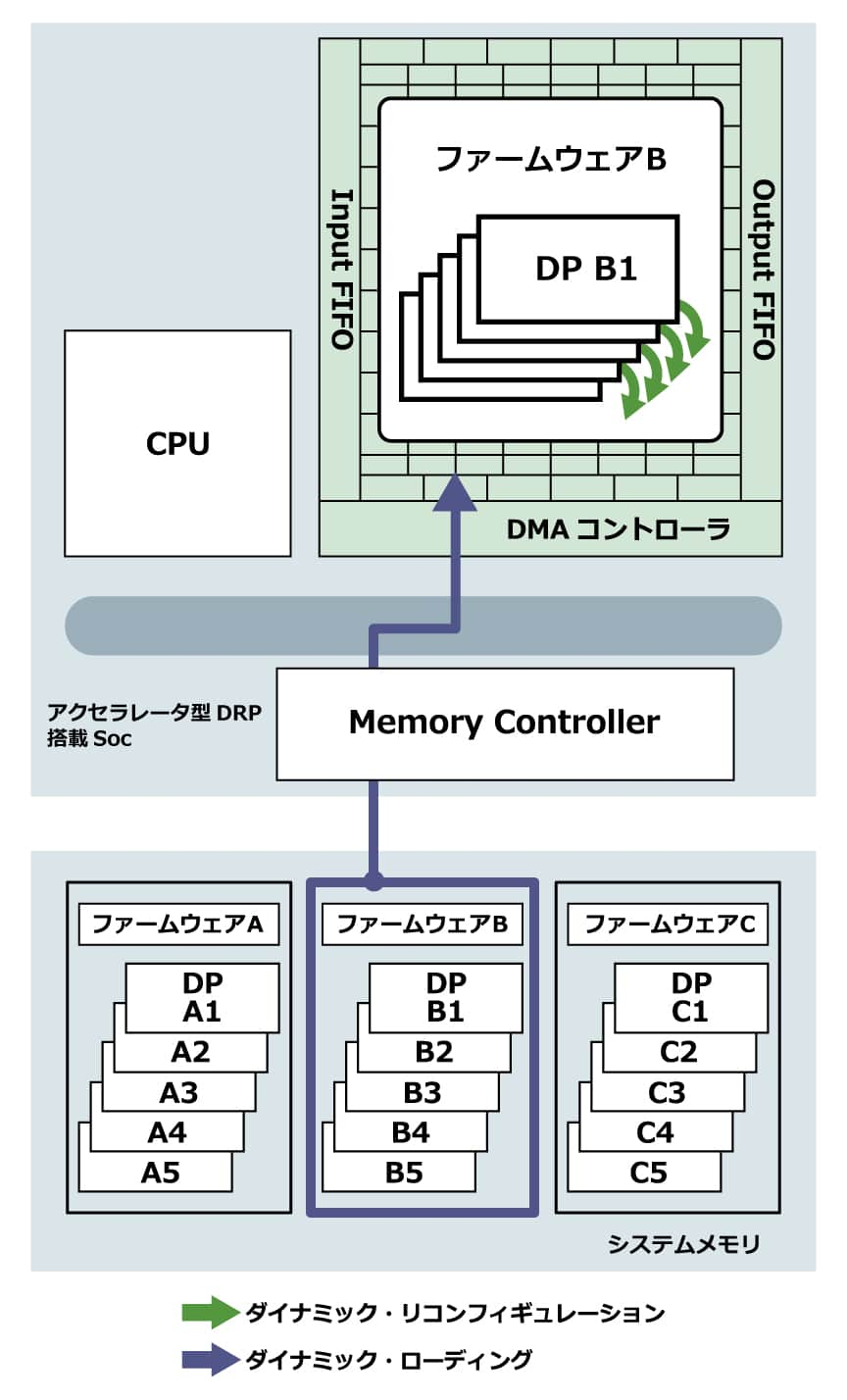
1. ダイナミック・リコンフィギュレーション

DRP内に最大64個(ASIC向け40nm IPコアの場合。)のデータパス(DP)情報を格納。限定的なプログラマブル演算器アレイ領域に実装する回路を、動的に再構成、 時分割で切り替えることで、実効的なロジック領域を拡張するものです。
0クロック (1ns以下)でDPを切り替えて処理を実行します。
2. ダイナミック・ローディング
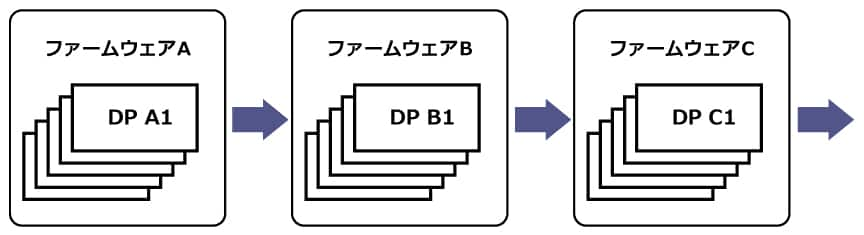
実行中に、外部メモリから別のファームウェアを追加で読み込み、全く異なる機能に対応したハードウェアに変更。チップに載りきらない巨大なアプリを時分割で実行します。
切り替え時間は数百μs程度(40nmコアの場合)。
アプリケーション
DRPは短期間で複雑な機能を実装できるため、仕様変更が多い先端アルゴリズムや通信プロトコル等を扱う機器に最適です。
採用実績(代表例)
- 業務用映像機材「XDCAMシリーズ」 (ソニー株式会社様)
- デジタル放送送出器「DDB-Lite」 (株式会社ヨーズマー様)
- デジタルカメラ製品
応用分野
- デジタルAV機器(画像、映像、音声)
- 複数種類のエンコーダのサポート
- エンコードとデコードの切り替え
- ブロードバンド通信機器
- 複数種類のプロトコルのサポート
- 将来の通信規格への対応
- OA機器
- 変倍、フィルタ、誤差拡散処理
- 複数のスキャナ入力フォーマット対応
- 産業機器
- モータ制御
- 計測機器