

「何を言うかだけでない。いかに言うか、でもある」。人間が効果的にコミュニケーションするために欠かせない真理を端的に現した格言がここにあります。人間が音声や音で相互理解することから、音を介した機械とのコミュニケーションが必然となる未来をもたらしました。
音声によるコミュニケーションの普及は、モノのインターネットと人工知能の導入拡大によって加速してきました。エンドポイントでのAIの統合と音声分析の進歩により、製品の可用性、プロダクトエクスペリエンスの消費が変化し、参加企業とイネーブラー型企業が共同してビジネスに取り組む新しいエコシステムが生まれています。オンラインとオフライン両方でシステムの実装が可能な、インテリジェントなエンドポイントソリューションは、インターネット/クラウドに常時接続する必要がありません。そのため、消費者および産業用アプリケーションにおける、リアルタイム音声分析に関連した多くの課題を解決する機会を生んでいます。さらに心理言語学的データ分析とアフェクティブ・コンピューティングの進歩によって、データ駆動型の音声モデリングで感情、態度、意図もまで推測できるようになりました。私たちと機械がコミュニケーションするのに音声が普通の手段となってきた今、音声認識と音声分析による意図の理解は今後ますます進んでいくでしょう。
VUIsの課題
音声ユーザーインターフェース(VUIs)の使用により、ユーザーは音声または音声コマンドを介してエンドポイントシステムに指示できます。現在、さまざまなアプリケーションで広く使われていますが、VUIsにはいくつかの制限があります。
- 低音質 - バックグラウンドノイズがあると、音声認識はどうしても困難になります。IoTの音声コントロールは、音がとてもクリアな場合にのみ問題なく動作でき、ノイズの多いうるさい環境では難しいのです。さらに音声対応アシスタントは、さまざまな言語やアクセントをサポートし、バックグラウンドノイズから発話を抽出できる場合にのみ、その性能を発揮します。
- 消費電力 – 音声コマンドシステムは、少なくとも1つのマイクと、ウェイクワードを認識するプロセッサーを起動する必要があるため、消費電力問題を避けられません。
- リアルタイム処理 - ネットワークの速度が遅い、または混雑していると、コマンドのレイテンシが発生し、ユーザーエクスペリエンスに影響を与えます。この問題は、集中型クラウドシステムに頼ることなく、音声コマンドをリアルタイムで処理する機能を備えた分散型インテリジェンスをエンドポイントに実装することで解決できます。
- 精度とノイズ耐性 - VUIシステムを設計する際、音声認識の精度とバックグラウンドノイズ耐性は常につきまとう問題です。内部および外部のノイズや、部屋のエコーなど複数の音源存在といった多くの障害があります。ここで、大元のコマンドを分離させ、エコーを除去し、バックグラウンドノイズを低減するという高度テクノロジーが必要となります。これには複数のマイクロフォン、ノイズ抑制とともに、ビームフォーミングとエコー除去などといった方法が考えられます。
そこで、ルネサスエレクトロニクスでは、製品メーカーが高性能な音声コマンドを簡単に統合できるよう、最先端のマイクロコントローラとパートナー企業向けインテリジェントな音声処理アルゴリズムを使用してこれらの課題を解決しています。性能や消費電力を損なうことなく、コストを最適化したVUI統合を可能にする汎用MCUをぜひ参照ください。
頑健な音声認識に欠かせない条件
ユーザーに魅力的なエクスペリエンスを提供するには、デバイスにいくつかのコンポーネントを装備した、高認識率の音声認識が欠かせません。
コマンド認識
音声対応デバイスで最も重要な機能の1つとして、音声入力から音声コマンドを識別する機能が挙げられます。ウェイクワードで音声コマンド認識システムがアクティブ化されると、音声入力を拾い、解釈し、テキストに起こします。最終的にこのテキストが、特定のタスクを実行するための入力またはコマンドの目的を果たします。
音声区間検出
音声区間検出(VAD)とは、音声信号およびバックグラウンドノイズから音声が存在する区間を区別するプロセスです。システム全体の消費電力を最適化するために利用されており、システムが常にアクティブ状態となり、不要な消費電力が発生するのを防いでいます。この VADアルゴリズムは、次の4段階に細分化できます。
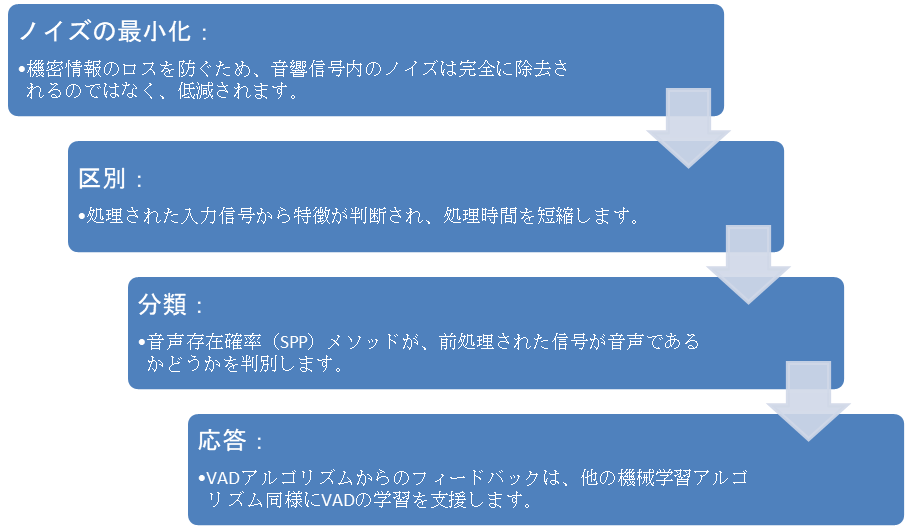
RA MCU製品ファミリとパートナー企業向け音声認識ミドルウェアに基づいて設計されたルネサスRA音声コマンドソリューションは、頑健なノイズ低減技術を誇り、高精度なVADを保証します。さらに、以下に挙げる主要な音声コマンド機能にも対応しています。
キーワードスポッティング
キーワードスポッティングシステム(KWS)は、音声対応デバイスで欠かせない機能の1つです。KWSではキーワードとフレーズを識別するための音声認識が重要となります。ユーザーがこれらの言葉を発するとエンドポイントでの認識プロセスが起動し、残りの質問部分に対応できるようにします。
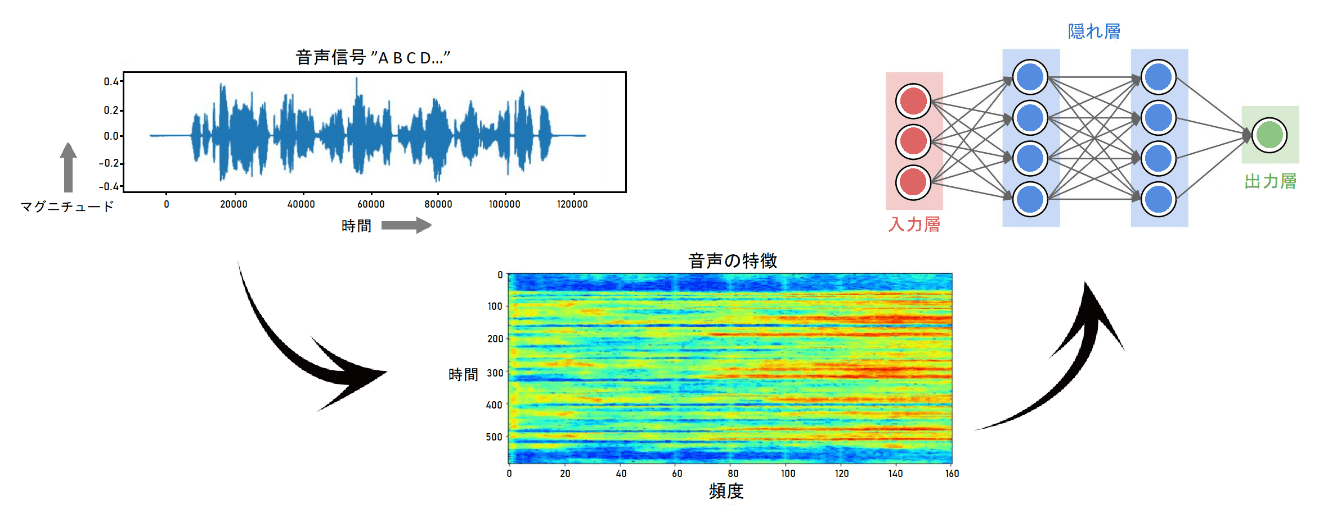
より良いハンズフリーユーザーエクスペリエンスを提供するには、正確でリアルタイムに応答するKWSが必要です。しかし電力バジェットを圧迫してしまう一面もあります。そこで、ルネサスでは高性能32ビットRAマイクロコントローラで実行可能な、パートナー企業向けに高度に最適化されたMLモデルを提供しています。事前学習済みDNNモデルが付属しており、高精度なキーワードスポッティングを可能にしています。
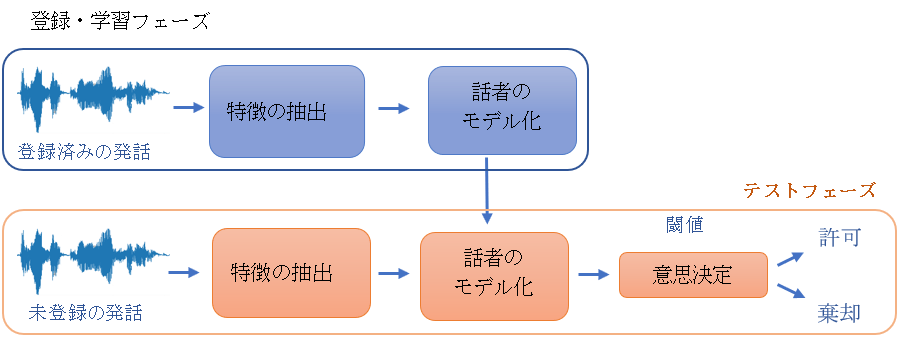
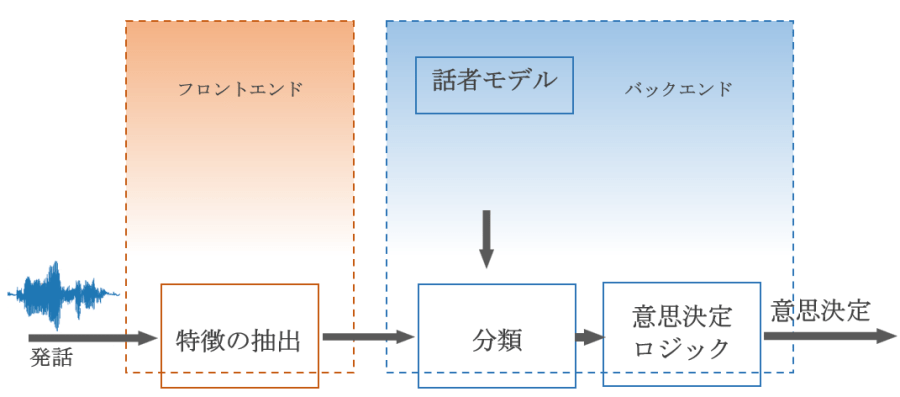
話者識別
話者識別とは、その名の通り、音声入力によって登録済みの話者を識別するプロセスです。この識別プロセスは、テキスト依存、テキスト非依存、およびテキスト指定型の3種類に分類できます。方言、発音、韻律(発話のリズム)、電話の使用方法など個々の特徴を取得して、DNNを学習させていきます。
音声によるなりすまし防止
なりすましは、侵入者が標的の話者になりすましてシステムへの不正アクセスを試みようとする詐欺の一種です。これを防止する策としては、システムのセキュリティを確保するなりすまし防止ソフトウェアの導入が効果的です。なりすまし攻撃は通常、自動話者認証(ASV)システムを狙います。音声合成や音声変換を使用するか、録音された音声を再生して、なりすまし音声を作成できるからです。これらの攻撃は、ASVシステムとの相互作用に応じて、直接的または間接的の2種類に分類できます。
- 直接的攻撃:マイクロフォンのセンサーや情報送信レベルで起き、物理的アクセスとも言われる。
- 間接的攻撃:ASVシステムソフトウェア内の特徴抽出、モデル、意思決定プロセスに侵入する。ロジカルアクセス攻撃とも言われる。
多言語/アクセント認識と理解
英語圏の国々でのアクセント認識には膨大な学習データが利用できるため、かなりスムーズに正確な予測ができます。しかし、英語が第一言語ではない国における組織・会社にとっての難点は、限られた量の学習データしかないため、音声認識の精度が低くなることです。量が不十分な学習データは、高精度の会話モデルを構築することを困難にします。ここで、パートナー企業向けのルネサスVUIソリューションのうちのひとつは44以上の言語に対応し、世界中のあらゆる組織・会社で使用できる高い適応力を誇ります。

高度マイクロコントローラに基づく、音声統合の採用を容易にする包括的なソリューションプラットフォームを実装させていますので、この機会をぜひ活用してください。当社のパートナー企業向けRA MCUベース音声コマンドソリューションは、低BOMコスト、統合セキュリティ、および低レイテンシを提供するだけでなく、エンドポイントでの実行機能も備えています。さらに、ローカルでの音声トリガー、コマンド認識、頑健なノイズ低減、音声区間検出、多言語サポートなど、そのほか付加価値的機能も網羅しています。また、パートナー企業向けに、ユーザーが簡単なテキスト入力で音声コマンドをすばやく作成できる、DNNベースの事前学習済み音声モデルを提供しています。これはフル機能の音声ソリューション開発スイートと、エンドポイント対応ミドルウェアを補うことで実現しています。つまり、そのまま使用していただくことも、それぞれのニーズに合わせて調整していただくことも可能なのです。